#GenerativeAgents#SyntheticUsers#SiliconSampling#가상사용자+7
AI InsightJun 15, 2026• 8 min read
UX 평가에 들어온 가상 사용자: AI는 실제 사용자를 대신할 수 있을까?
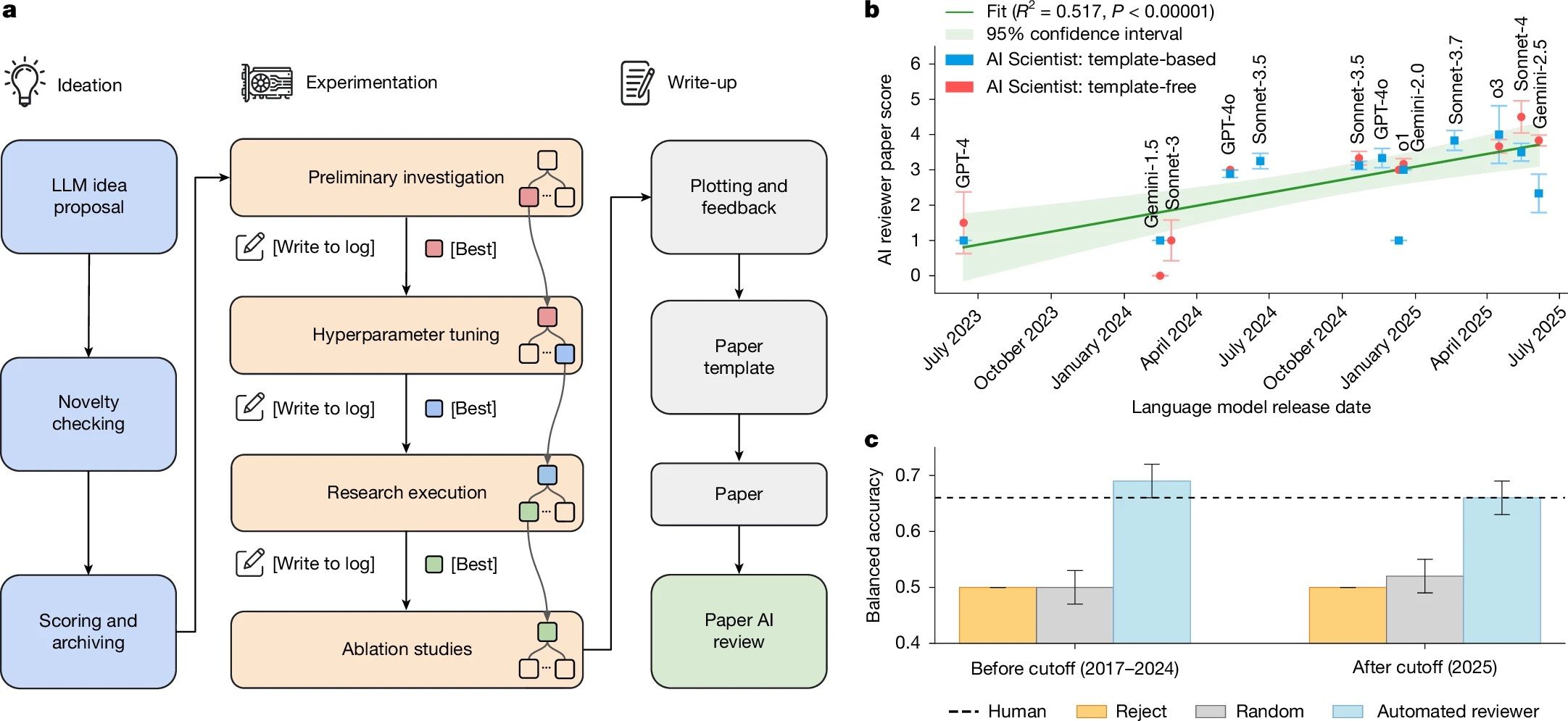
사용자 테스트는 느리고 비싸지만, AI 가상 사용자는 언제든 빠르게 피드백을 줍니다. Generative Agents에서 Synthetic Users로 이어지는 흐름을 따라, AI가 UX 평가에서 무엇을 도울 수 있는지, 실제 사용자와 어디서 달라지는지, 그리고 어디까지 맡겨도 되는지 짚어봅니다.