Tech
나만의 딥리서치 만들기: 작은 오픈 소스 언어 모델로도 딥리서치를 만들 수 있을까?

최근 LLM과 이를 기반으로 한 AI 에이전트 시스템들이 발전함에 따라, 사람들이 원하는 정보를 획득하는 방법에도 큰 변화가 일어나고 있습니다. 구체적으로, 사람이 원하는 정보를 찾기 위해 구글링을 하고, 일일이 웹 페이지들을 조회하면서 정보를 정리하던 시대에서, AI 에이전트가 알아서 웹 검색과 정보 정리를 해주는 시대로의 전환이 이루어지고 있습니다.
OpenAI, Google과 같은 기업들에서 발표한 '딥리서치 (Deep Research)' 시스템은 이러한 변화를 단적으로 보여줍니다.

딥리서치 시스템이란?
그렇다면 딥리서치 시스템이란 정확히 무엇일까요? 단순히 "검색해서 알려줘" 수준을 넘어, 복잡하고 답이 정해져 있지 않은 문제를 해결하기 위해 AI가 스스로 연구 계획을 세우고 실행하는 시스템을 말합니다. 이 과정은 크게 두 가지 핵심 프로세스로 정의됩니다.
- 딥서치(Deep-Search) 단계: 복잡한 질문을 여러 개의 하위 질문으로 스스로 쪼개고(Partitioning), 검색 엔진과 웹 브라우저 등 다양한 도구를 수십 번 오가며 필요한 정보를 집요하게 수집하는 과정입니다.
- 합성(Synthesize) 단계: 이렇게 수집된 파편화된 정보들을 하나로 엮어(Integration), 논리적이고 근거가 확실한 하나의 완결된 보고서나 결론으로 정리하는 과정입니다.
이러한 시스템들은 사람이 몇 시간, 심지어 며칠이 걸려야 할 방대한 자료 조사를 단 몇 분 만에 끝내는가 하면, 수십 개의 출처를 종합해 전문가 수준의 리포트를 뚝딱 만들어내기도 합니다. 단순한 정보 검색을 넘어, 마치 유능한 보조 연구원처럼 스스로 판단하고 정리하는 수준에 도달한 것이죠.
나만의 딥리서치 시스템을 구축할 수 있을까?
하지만 이러한 고성능 시스템들은 대부분 GPT-5나 Gemini와 같은 빅테크 기업의 거대 모델 기반입니다. 이는 곧 높은 API 비용과 데이터 보안 이슈로 이어지며, 우리가 직접 통제 가능한 '나만의 딥리서치 시스템'을 구축하기에는 현실적인 제약이 따릅니다.
이를 극복하기 위해 오픈 소스 진영에서도 꾸준히 자체적인 딥리서치 구현을 시도해왔습니다. 하지만 결과는 냉혹했습니다. 상용 모델(Proprietary models)과 비교했을 때, 오픈 소스 모델들은 복잡하고 긴 호흡의 리서치 작업을 수행하는 데 있어 여전히 뚜렷한 '성능 격차(Performance Gap)'를 보이며 고전해왔기 때문입니다.
그러나 최근 공개된 연구 "Fathom-DeepResearch"는 놀랍게도 단 4B(40억) 파라미터 크기의 작은 오픈 소스 모델(SLM)로도 최상위권의 딥리서치 성능을 낼 수 있음을 증명했습니다.
오늘은 이 논문을 바탕으로, 어떻게 작은 모델이 거대 모델들을 제치고 강력한 리서치 에이전트가 될 수 있었는지, 그 구체적인 레시피를 하나씩 뜯어보겠습니다.
Paper name: Fathom-DeepResearch: Unlocking Long Horizon Information Retrieval and Synthesis for SLMs
Link: https://arxiv.org/pdf/2509.24107
나만의 딥리서치, 오픈 소스 모델로 구축하려면?
왜 오픈 소스 모델들은 낮은 성능을 보였을까?
기술에 관심 있는 분이라면 이런 의문을 가졌을 겁니다.
"오픈 소스 모델(Llama, Qwen 등)에 검색 도구(Tool)만 붙이면 되는 거 아니야?"
하지만 실제로 구현해보면 오픈 소스 모델들은 딥리서치 작업에서 처참하게 실패하곤 했습니다. 논문에서는 그 이유를 크게 두 가지로 분석합니다.
- 지속적인 도구 사용 능력 부족 (Lack of sustained tool usage): 리서치는 한 번 검색으로 끝나지 않습니다. 꼬리에 꼬리를 무는 질문을 스스로 던지며 20번, 30번 검색을 이어가야 하는데, 기존 모델들은 중간에 길을 잃거나 같은 검색어를 반복(Loop)하다 멈춰버립니다.
- 정보 합성 능력 부족 (Lack of synthesis capability): 수집한 정보를 바탕으로 '보고서'를 쓰는 능력입니다. 단순히 검색 결과를 나열하는 게 아니라, 인사이트를 도출해야 하는데 기존 모델들은 단답형 문제 풀이(Math/Code)에만 최적화되어 있었습니다.
이 문제를 해결하기 위해 본 연구에서는 '데이터', '학습 알고리즘', '보상 체계' 세 가지 측면에서 혁신적인 접근을 시도했습니다.
레시피 1: "검색 없이는 못 푸는 문제"를 만들어라 (DuetQA)
딥리서치 모델을 만들 때 가장 먼저 부딪히는 벽은 아이러니하게도 '모델이 이미 너무 많은 것을 알고 있다'는 점입니다.
그동안 딥리서치나 검색 에이전트 학습에 주로 활용되었던 기존의 QA 데이터셋(TriviaQA, HotpotQA)은 대부분 과거의 유명한 사실들을 다룹니다. 그러나 최근 LLM들은 학습 과정에서 이런 내용을 이미 다 외워버렸습니다. 그렇다 보니 "에펠탑은 어디에 있나?"라고 물으면, 모델은 검색 도구를 쓰지 않고도 자기 기억(Parametric Knowledge)에서 바로 답을 꺼냅니다.
이게 왜 문제일까요?
우리가 가르치고 싶은 건 '모르는 정보를 찾아가는 과정(Process)'입니다. 어떤 검색어를 입력해야 할지, 결과를 보고 무엇을 클릭해야 할지 판단하는 능력을 키워야 하는데, 모델이 이미 답을 알고 있다면 이 과정을 건너뛰어 버립니다. 결과적으로 모델은 검색을 적절하게 활용하는 방법 자체를 학습하지 못하게 됩니다.
그래서 "검색을 안 하면 절대 못 푸는 문제"가 필수적입니다. 모델의 학습 데이터에 없는 최신 정보(2024년 이후)나, 웹 구석구석을 뒤져야만 나오는 지엽적인 정보를 물어봐야 합니다. 그래야 모델이 비로소 자신의 지식만으로는 해결할 수 없음을 깨닫고, 실제로 웹을 탐색하며 정보를 '수집'하는 법을 배우게 됩니다.
이 연구에서는 DuetQA라는 새로운 데이터셋을 구축하기 위해, 독창적인 데이터 생성 파이프라인을 제안합니다.
- 멀티 에이전트 자가 생성 (Multi-agent Self-play): 두 개의 AI 모델(생성자)이 웹 검색을 통해 2024년 이후의 최신 정보나 구체적인 사실을 찾아내고, 이를 바탕으로 복잡한 질문을 만듭니다.
- 엄격한 필터링: 이렇게 만든 질문을 또 다른 AI(검증자)에게 풀게 시킵니다. 이때, "검색 도구 없이도 맞출 수 있는 문제"는 과감히 버립니다. 오직 검색을 통해서만 답을 찾을 수 있는 문제 5,000개를 엄선하여 모델을 학습시킵니다.
레시피 2: RL 학습이 깨지지 않게 잡아라 (RAPO)
기술적 구현에서 가장 흥미로운 부분은 강화학습(RL) 기법입니다. 보통 GRPO(Group Relative Policy Optimization)를 사용해 모델을 학습시키는데, 딥리서치처럼 호흡이 긴 작업에서는 GRPO가 자주 실패합니다. 모델이 검색을 하다 말고 이상한 토큰을 뱉거나, 학습이 발산해버리는 것이죠.그렇다면 구체적으로 왜 이런 현상이 발생할까요? 논문에서는 크게 두 가지 원인을 지적합니다.
- 분포 변화(Distribution Shift)로 인한 디코딩 불안정: 모델이 검색 도구를 사용하고 외부 정보를 받아오는 과정이 반복되면, 모델은 자신이 평소 학습했던 데이터 분포와는 전혀 다른 낯선 문맥(Context)에 놓이게 됩니다. 이로 인해 모델이 다음에 올 말을 생성할 때 확률 분포가 망가지면서 말을 더듬거나, 했던 말을 무한 반복하는 등 '고장 난' 행동(Decoding Instability)을 보이게 됩니다.
- 보상 붕괴(Reward Collapse): GRPO는 그룹 내에서 '누가 더 잘했나'를 비교(상대 평가)하여 학습하는 방식입니다. 그런데 딥리서치 시스템이 다루는 어려운 작업에서는 그룹 내 모든 시도가 실패해버리는 경우가 빈번합니다. 모두가 0점을 받거나 낮은 점수를 받으면 비교 우위를 가릴 수 없게 되고, 이로 인해 학습 신호(Gradient)가 사라지거나 불안정해져 학습 자체가 와르르 무너지는 현상이 발생합니다.
이를 해결하기 위해 RAPO (Reward-Aware Policy Optimization)라는 개선된 알고리즘을 도입했습니다.
- 데이터 가지치기 (Dataset Pruning): 이미 너무 잘 푸는 문제는 학습에서 제외합니다. 학습 효율을 높이고 모델이 어려운 문제에 집중하게 합니다.
- 이점 스케일링 (Advantage Scaling): 배치(Batch) 내에서 유의미한 정보를 주는 그룹에 더 큰 가중치를 둡니다.
- 리플레이 버퍼 (Replay Buffer): 모델이 정답을 못 찾고 헤맬 때, 과거에 성공했던 경험(Trajectory)을 슬쩍 끼워 넣어 학습의 방향을 잃지 않게 가이드합니다.
이 결과, 모델은 긴 호흡의 리서치 과정에서도 길을 잃지 않고 안정적으로 학습할 수 있게 되었습니다.
레시피 3: '의미 없는 검색을' 구분하라 (Steerable Reward)
AI 에이전트에게 "도구를 많이 쓰면 좋다"고 가르치면, 에이전트는 무의미한 검색어만 바꿔가며 클릭 수만 늘리는 '의미 없는 검색'을 시작합니다. 이를 막기 위해 조종 가능한 단계별 보상(Steerable Step-Level Reward) 시스템을 도입했습니다.
학습 과정에서 GPT-4와 같은 상위 모델이 에이전트의 행동을 감시하며 꼬리표를 붙입니다.
- UniqueSearch: "오, 이건 새로운 관점의 검색어네?" → 보상 (Reward)
- RedundantSearch: "아까랑 똑같은 내용이잖아." → 패널티 (Penalty)
- Verification: "정보가 맞는지 크로스 체크를 하네?" → 보상 (Reward)
단순히 정답을 맞혔느냐(Outcome Reward)뿐만 아니라, "과정이 얼마나 훌륭했는가"를 평가함으로써, 모델이 '의미없는 검색'이 아닌 진짜 '탐구'와 '검증'을 하도록 유도했습니다.
시스템 아키텍처: 검색따로, 정리따로
마지막으로 Fathom-DeepResearch는 하나의 모델이 모든 걸 다 하려 하지 않고, 역할을 철저히 분리했습니다. 앞서 설명한 딥서치와 합성 단계를 각각 전담하는 두 개의 특화 모델을 사용합니다.
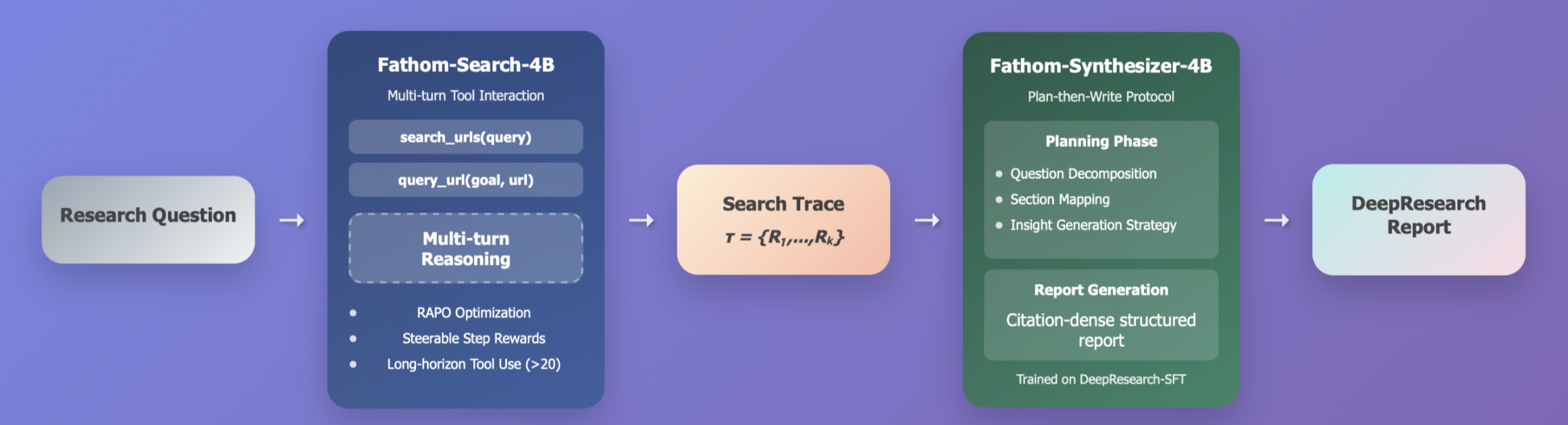
- 🕵️ Fathom-Search-4B (딥서치 단계 수행):
- 앞서 정의한 딥서치(Deep-Search) 단계를 전담하여, 오직 정보 수집과 검증에만 집중합니다.
- Qwen3-4B를 기반으로 학습되었으며, 20회 이상의 긴 검색 턴을 소화하며 정보를 집요하게 긁어모읍니다.
- 📝 Fathom-Synthesizer-4B (합성 단계 수행):
- 합성(Synthesize) 단계를 맡아, Fathom-Search-4B가 수집한 로그(Trace)를 바탕으로 최종 보고서를 작성합니다.
- "Plan-then-Write" 프로토콜을 따라, 먼저 목차와 인용 계획을 세우고(Plan), 그 뒤에 정확한 인용(Citation)이 달린 고품질 보고서를 작성(Write)합니다.
Fathom-DeepResearch의 성능
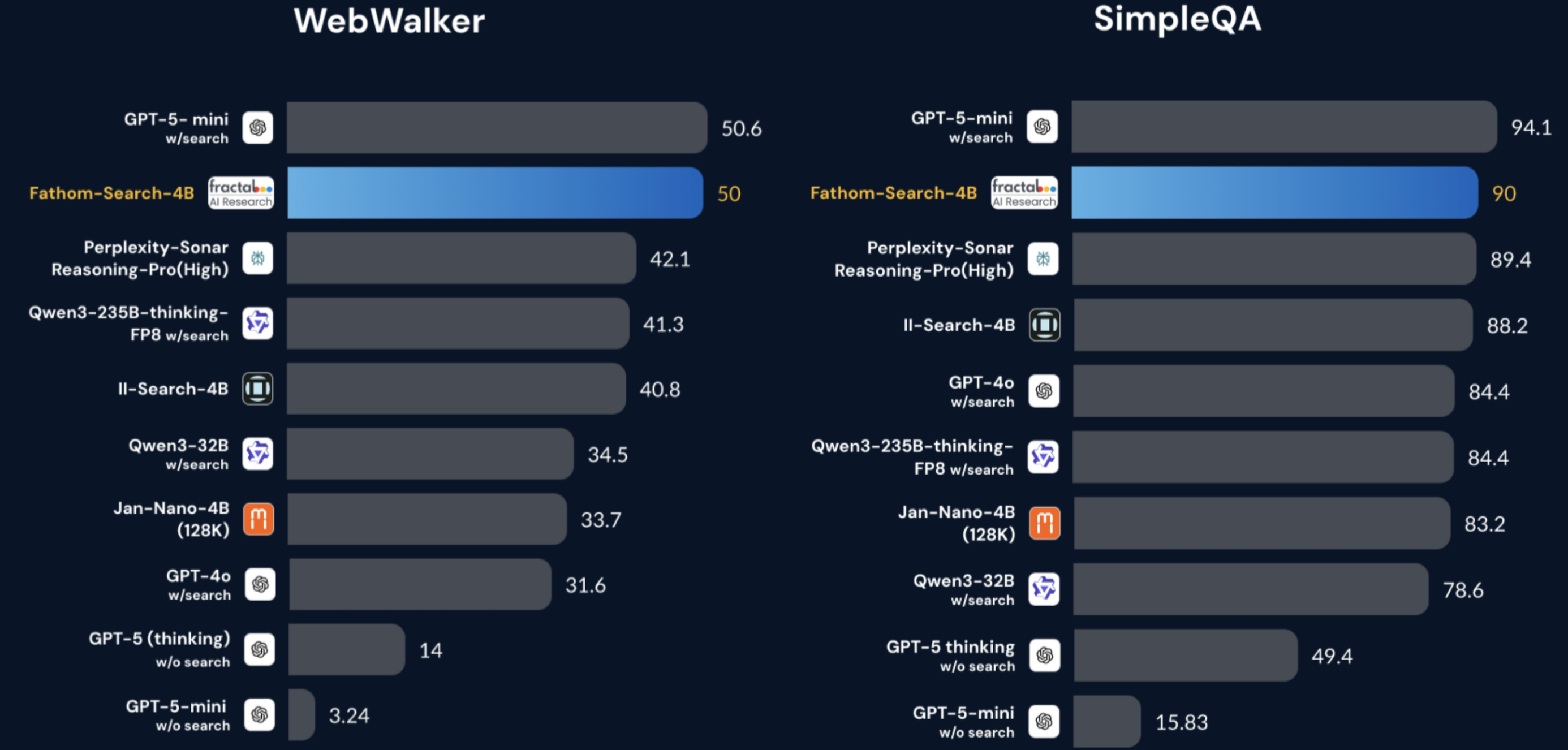
그렇다면, 이렇게 구성된 Fathom-DeepResearch의 성능은 어떨까요? 실험 결과, 단 4B 파라미터의 모델로도 상용 모델에 필적하거나 이를 상회하는 성능을 보여주었습니다.
- DeepSearch 벤치마크: SimpleQA, FRAMES 등 주요 검색 과제에서 GPT-4o(Search 포함)를 능가했습니다. 특히 SimpleQA에서는 90.0%의 정답률을 기록하며 GPT-4o(84.4%) 대비 유의미한 성능 향상을 입증했습니다.
- DeepResearch 벤치마크: 종합적인 보고서 작성 능력을 평가하는 벤치마크에서도 종합 점수 45.47%를 기록, Perplexity-DeepResearch(42.25%)와 GPT-4o Search(35.10%)를 앞질렀습니다.
나만의 딥리서치 시스템을 만드는 핵심 전략들
지금까지 Fathom-DeepResearch를 살펴보며, 과연 어떻게 작은 오픈 소스 모델로 거대 모델에 버금가는 성능을 낼 수 있었는지 확인해 보았습니다.
이 내용을 바탕으로, '나만의 딥리서치 시스템'을 구축하기 위해 반드시 챙겨야 할 핵심 요소들을 정리해 보겠습니다.
1. 데이터적인 관점: "도메인에 특화된 고난도 데이터 구축"
모델이 스스로 검색하는 능력을 기르려면, 데이터의 질이 무엇보다 중요합니다.
- 고품질 검색 데이터: 모델이 기존 지식만으로는 절대 대답할 수 없는, 반드시 검색이 필요한 데이터를 모으세요. (예: 최신 뉴스, 실시간 통계, 구체적인 사실 검증)
- 도메인 특화: 만약 여러분이 금융, 법률, 의학 등 특정 분야에 관심이 있다면, 그 도메인에 특화된 질문과 검색 데이터를 집중적으로 학습시키세요. 범용 모델보다 훨씬 깊이 있는 '나만의 도메인 리서치 에이전트'를 만들 수 있습니다.
2. 학습적인 관점: "과정을 평가하는 정교한 보상 설계"
좋은 데이터를 확보했다면, 모델이 이를 제대로 소화할 수 있도록 학습 전략을 짜야 합니다.
- Reward Engineering: 단순히 정답(Outcome)만 맞혔는지 보는 게 아니라, "얼마나 효율적으로 검색했는가?", "다양한 소스를 검증했는가?"와 같은 과정을 평가하는 보상 체계를 설계하는 것이 핵심입니다.
- 이러한 보상 체계를 통해, 모델이 "의미 있는 정보를 검색할 때"마다 보상을 주는 것이 가장 중요한 요소 중 하나입니다.
이 두 가지 관점만 확실히 잡는다면, 작은 오픈 소스 모델만으로 충분히 강력하고 효율적인 나만의 딥리서치 시스템을 구축할 수 있습니다. 이제 여러분의 차례입니다. Fathom-DeepResearch가 증명한 이 가능성이, 여러분의 도메인에서 새로운 가치를 창출하는 시작점이 되기를 바랍니다.