Tech
AI는 비디오만 보고 세상을 이해할 수 있을까? V-JEPA 2가 제시하는 월드 모델의 가능성


생성형 AI 이후, 다음 가능성은 어디에 있을까?
ChatGPT가 촉발한 생성형 AI 열풍 이후, "그다음은 무엇인가?"라는 질문이 업계 전반에서 나오고 있습니다. 벤처 캐피털 a16z는 2026년 빅 아이디어 중 하나로 Physical AI를 선정하며, "AI가 화면 밖으로 나와 공장, 인프라, 물류로 진입하고 있다"고 진단했습니다(a16z, 2026). 텍스트를 잘 다루는 것만으로는 물리 세계에서 작동하는 AI를 만들기 어렵다는 인식이 확산되고 있는 것입니다.
이 흐름에서 자주 언급되는 인물이 Yann LeCun(Meta 수석 AI 과학자, 튜링상 수상자)입니다. 그는 대규모 언어 모델(LLM)을 "토큰 생성기"로 규정하면서, 텍스트로는 세상의 물리적 구조를 이해하는 데 한계가 있다는 입장을 밝혀왔습니다. 그가 제안하는 대안적 방향은, 인간처럼 시각 정보를 통해 세상의 내부 모델(월드 모델)을 구축하고, 그 위에서 미래를 예측하는 것입니다. 2025년 11월, LeCun은 이 방향에 대한 확신을 행동으로 옮기기도 했습니다. Meta를 떠나 AMI(Advanced Machine Intelligence) 연구에 집중하는 새로운 조직을 설립한 것입니다(CNBC, 2025).
물론 월드 모델을 향한 경쟁은 Meta만의 이야기가 아닙니다. NVIDIA의 Cosmos, Google DeepMind의 Genie 3, Wayve의 GAIA-2 등 다양한 접근이 동시에 탐색되고 있습니다. LeCun의 팀이 만들어낸 V-JEPA 2의 경우, 100만 시간의 인터넷 비디오를 보고 세상의 구조를 학습한 뒤, 단 62시간의 로봇 데이터만으로 처음 보는 환경에서 로봇 팔을 움직이는 데 성공했습니다.
이 글에서는 V-JEPA 2가 어떤 원리로 작동하는지, 그 배경이 되는 JEPA 패러다임이 기존 접근과 어떻게 다른지를 I-JEPA → V-JEPA → V-JEPA 2의 흐름을 따라 소개합니다.
JEPA란 무엇인가? 기존 자기지도학습과 뭐가 다를까?
V-JEPA 2를 이해하려면, 먼저 이미지 자기지도학습의 세 가지 접근 방식을 비교할 필요가 있습니다. 각각이 "이미지의 가려진 부분을 어떻게 처리하는가?"에 대해 서로 다른 답을 내놓습니다.
이미지를 이해하는 세 가지 방법

(a) 결합 임베딩 방식은 같은 이미지의 서로 다른 시각적 변환(증강)을 만들어서, 두 변환이 같은 표현 공간에 매핑되도록 학습합니다. 새의 정면과 측면 사진이 비슷한 특성을 갖도록 만드는 식입니다. DINOv3(Meta, 2025)가 대표적이며, 학생-교사(Student-Teacher) 구조와 지수 이동 평균(EMA) 업데이트를 사용합니다. 강력한 시각적 표현을 학습할 수 있지만, 시각적 증강에 의존하기 때문에 비디오의 시간 관계를 포착하는 데는 한계가 있습니다.
(b) 생성 방식은 마스킹된 이미지의 원본 픽셀을 복원하는 방식입니다. MAE(CVPR 2022)가 대표적입니다. 로컬 구조, 텍스처, 경계선 같은 세부 사항을 잘 포착하지만, 이해에 꼭 필요하지 않은 배경이나 조명 같은 저수준 디테일까지 전부 복원해야 합니다. 그만큼 계산 비용이 높습니다.
(c) JEPA(결합 임베딩 예측 구조)는 이 두 가지와는 다른 방향을 취합니다. 가려진 부분의 픽셀을 복원하는 대신, 잠재 공간에서 의미 표현을 예측합니다. 시험공부에 비유하면, 교과서를 한 글자씩 베끼며 외우는 것(픽셀 복원)이 아니라, 핵심 개념과 흐름을 이해하는 것(의미 예측)에 가깝습니다. 이미지를 패치로 나누고, 일부를 가리고, 보이는 부분을 인코딩한 뒤, 가려진 부분의 "의미"를 예측하는 구조입니다.
I-JEPA는 이미지의 의미를 어떻게 예측할까?
I-JEPA의 학습 과정을 단계별로 살펴보겠습니다.
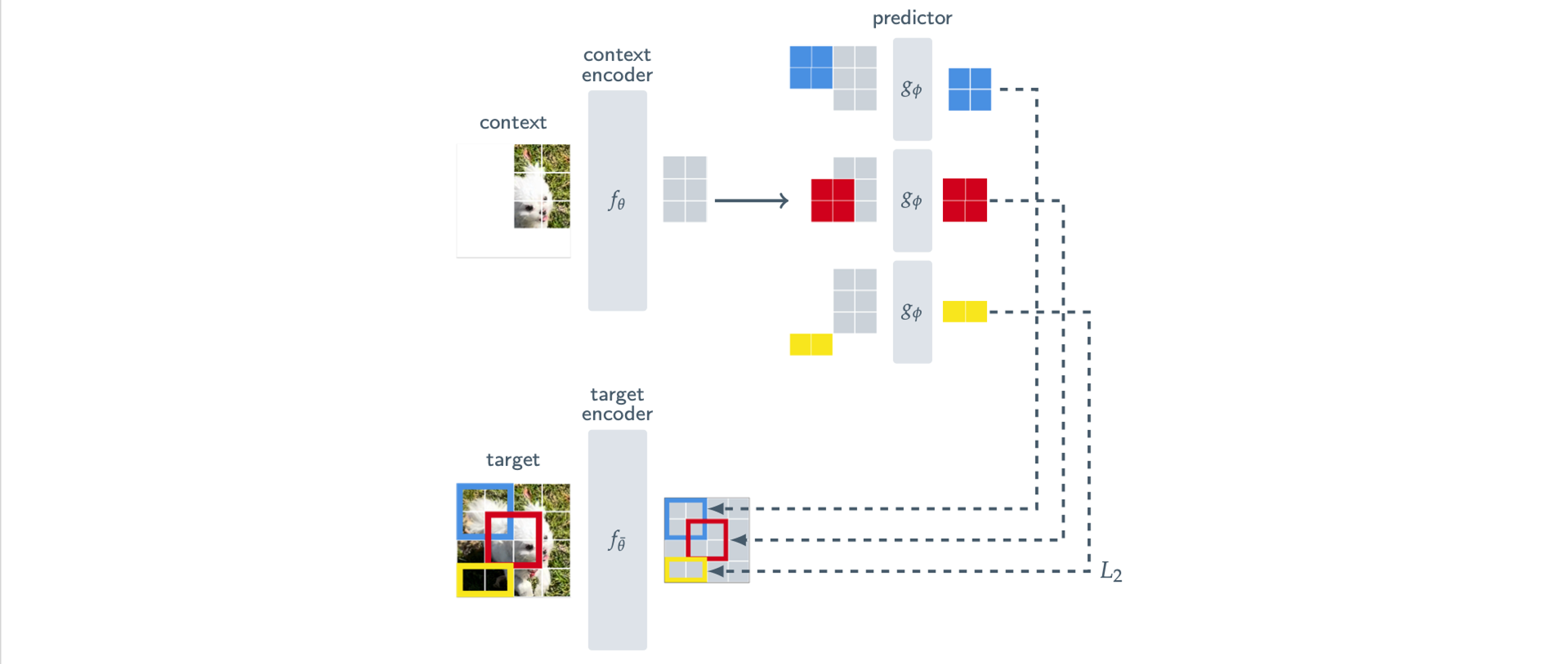
- 맥락 인코더: 이미지의 대부분(85~100%)을 보고 인코딩합니다.
- 타겟 인코더: 작은 타겟 블록(15~20%)을 인코딩합니다.
- 예측기: 맥락 특성과 가려진 위치 정보를 받아서, 타겟 블록의 특성을 예측합니다.
여기서 핵심은, 예측기가 예측하는 것이 "가려진 영역의 픽셀"이 아니라 "가려진 영역의 의미적 표현"이라는 점입니다. 강아지 사진에서 얼굴이 가려졌다면, I-JEPA는 강아지 얼굴의 텍스처를 복원하지 않습니다. 대신 "여기에 강아지 얼굴에 해당하는 의미가 있다"는 것을 잠재 공간에서 예측합니다. 이런 방식으로 모델은 세상의 의미 구조를 학습하게 됩니다.
학습 시, 예측기와 맥락 인코더는 직접 업데이트되고, 타겟 인코더는 맥락 인코더를 지수 이동 평균(EMA) 방식으로 천천히 따라갑니다. 타겟 인코더를 안정적으로 유지하면서도 점진적으로 개선하는 설계입니다.
V-JEPA는 비디오에서 어떻게 시간을 이해할까?
I-JEPA의 개념을 비디오로 확장한 것이 V-JEPA입니다. 기본 구조는 동일합니다. 비디오에서 보이는 부분을 인코딩하고, 가려진 부분의 특성을 예측합니다.
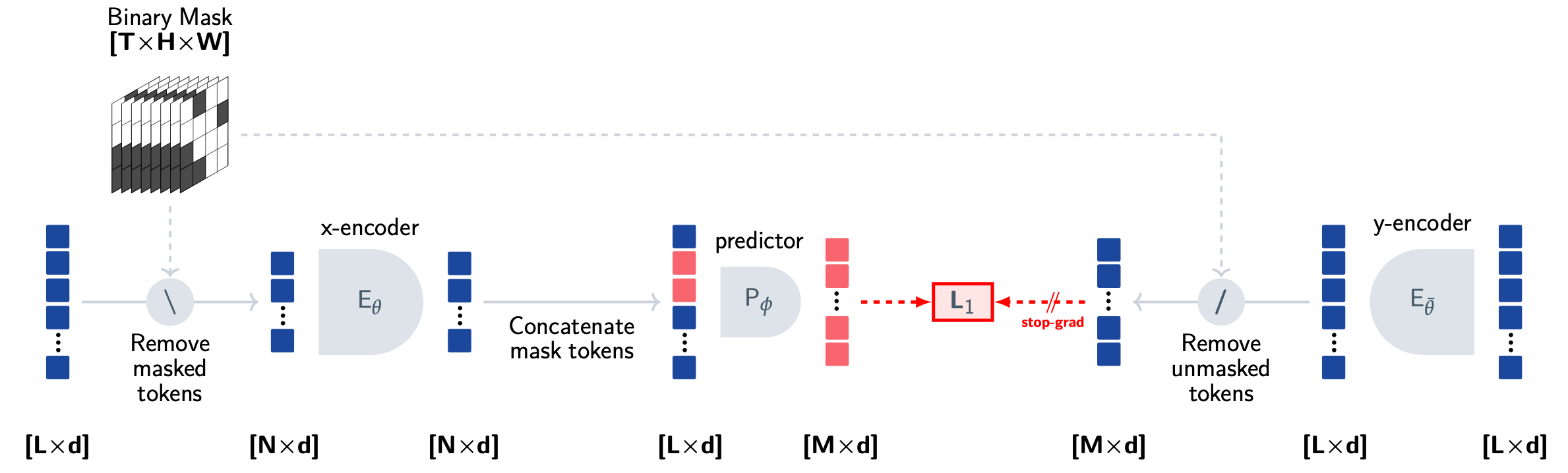
"Revisiting Feature Prediction for Learning Visual Representations from Video" (Meta 2024)
비디오에서 가장 까다로운 문제는 무엇일까?
비디오 데이터의 가장 큰 난관은 시간적 중복입니다. 연속 프레임 간 차이가 매우 작기 때문에, 무작위로 작은 영역을 가리면 모델이 인접 프레임에서 답을 "베끼는" 방식으로 문제를 풀어버립니다. 이러면 예측이 단순한 보간 문제로 전락합니다.
V-JEPA는 이 문제를 마스킹 전략으로 해결합니다.
- 근거리 마스크: 각 프레임의 15% 영역을 8개 블록으로 가림
- 원거리 마스크: 각 프레임의 70% 영역을 2개 블록으로 가림
핵심은 이 블록들이 전체 시간 축에 걸쳐 지속된다는 것입니다. 특정 공간 영역이 처음부터 끝까지 가려져 있으니, 모델이 인접 프레임에서 답을 찾을 수 없습니다. 진정한 의미적 예측을 강제하는 설계입니다.
특성 예측은 픽셀 예측보다 얼마나 효과적일까?
동일한 ViT-L/16 모델에서 예측 대상만 바꿨을 때, 특성 예측이 모든 벤치마크에서 앞섭니다. Kinetics 400(행동 인식)에서 68.6 → 73.7, Something-Something-v2(시간 이해)에서 66.0 → 66.2, ImageNet-1K에서 73.3 → 74.8로 향상됩니다. 아키텍처는 똑같고, "무엇을 예측하느냐"만 바꿨을 뿐인데 이 정도의 차이가 나타납니다.
기존 픽셀 예측 방식의 대표 모델들과 비교한 결과도 주목할 만합니다.
- OmniMAE: 24억 샘플 학습, K400 65.6 / SSv2 60.6
- VideoMAE: 4.1억 샘플 학습, K400 77.8 / SSv2 65.5
- Hiera: 7.7억 샘플 학습, K400 75.5 / SSv2 64.2
- V-JEPA: 2.7억 샘플 학습, K400 80.8 / SSv2 69.5
V-JEPA는 가장 적은 데이터로 학습했음에도 주요 지표에서 앞서는 결과를 보여줍니다. 이 결과만 놓고 보면, "무엇을 예측할 것인가"라는 설계 선택이 데이터 양 못지않게 중요할 수 있음을 시사합니다.
V-JEPA 2는 무엇이 달라졌을까?
V-JEPA가 비디오의 의미를 이해하는 인코더를 만들었다면, V-JEPA 2는 한 단계 더 나아간 시도입니다. "이해한 세상 위에서 행동까지 계획할 수 있는가?"라는 질문을 던집니다.
Assran, M. et al. "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning" (Meta 2025) 코드: GitHub · 블로그
왜 인터넷 비디오에 주목하는 걸까?
기존 월드 모델은 로봇이 직접 환경을 탐색하며 모은 행동-상태 데이터에 의존했습니다. 하지만 이런 데이터를 대규모로 수집하기란 비용도 높고 환경도 제한적입니다. 반면 인터넷에는 이미 수억 시간의 비디오가 존재합니다.
V-JEPA 2가 탐색하는 가설은 이것입니다. 행동 레이블 없이 관찰만으로도 물리 세계에 대한 지식을 상당 부분 학습할 수 있지 않을까? 운전을 배울 때, 직접 핸들을 잡기 전에 옆에서 다른 사람의 운전을 오래 지켜보면 도로 위에서 벌어지는 일들에 대한 감각이 생기는 것과 비슷한 발상입니다.
Meta의 공식 블로그에서도 이 점을 강조합니다. V-JEPA 2는 비디오를 통해 "사람이 물체와 어떻게 상호작용하는지, 물체가 물리 세계에서 어떻게 움직이는지, 물체 간 상호작용이 어떻게 이루어지는지"를 학습했다고 설명합니다.
V-JEPA에서 무엇이 바뀌었나?
V-JEPA 2는 V-JEPA의 구조를 유지하면서 두 가지를 변경합니다.
첫째, 학습 규모를 대폭 확장했습니다.
- 데이터: 200만 개 → 2,200만 개
- 모델 크기: ViT-L(3억 파라미터) → ViT-g(12억 파라미터)
- 학습 반복: 9만 회 → 25.2만 회
- 해상도: 고정 → 점진적 확대(낮은 해상도에서 시작해 높은 해상도로 전환)
둘째, 행동 조건부 예측기를 추가했습니다. V-JEPA가 "이 장면에서 무슨 일이 벌어지고 있는가?"를 이해하는 데 초점을 맞췄다면, 이 예측기는 "현재 상태에서 이 행동을 취하면 다음에 무슨 일이 벌어질까?"를 예측합니다. 이 부분이 로봇 제어 가능성을 열어주는 핵심 모듈입니다.
로봇은 비디오를 보고 어떻게 행동을 계획할까?
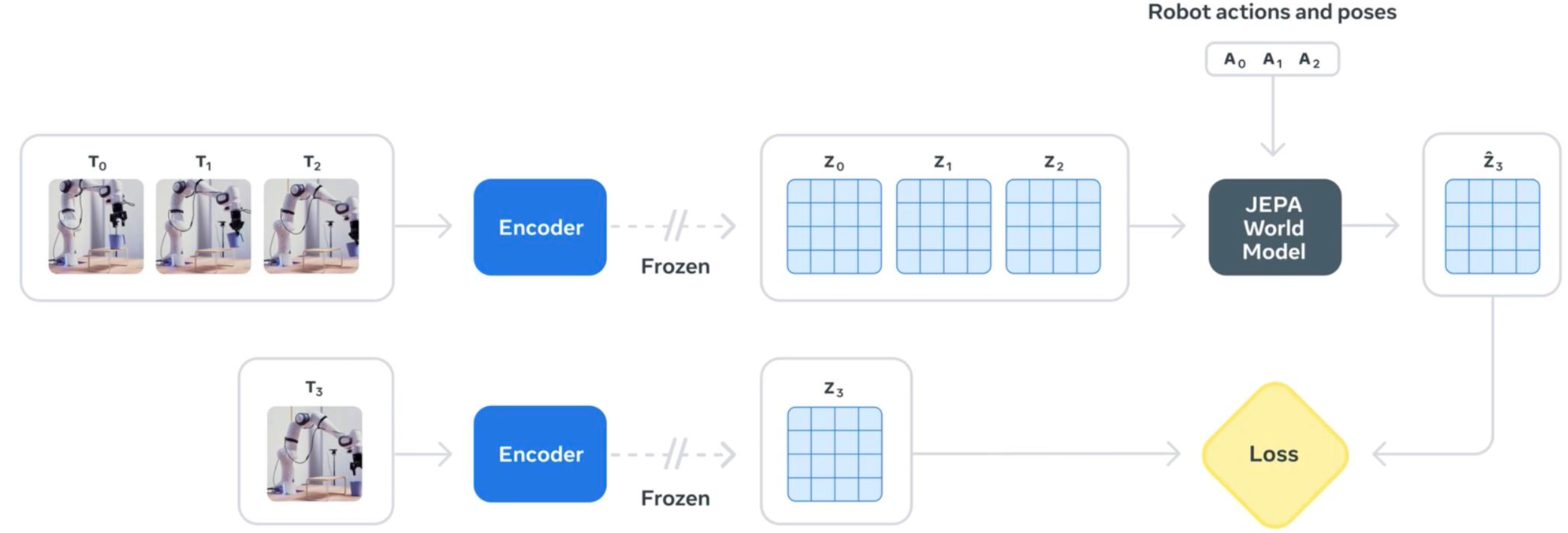
"상상"으로 행동을 계획하는 과정
V-JEPA 2가 로봇을 제어하는 과정은 체스에 비유하면 이해하기 쉽습니다.
- 현재 상황을 본다 (카메라 입력 → 인코더)
- "이 행동을 하면 어떻게 될까?"를 머릿속으로 시뮬레이션한다 (예측기)
- 상상한 결과가 목표에 가까워지도록 행동을 조정한다
별도의 보상 함수나 강화학습 없이, 잠재 공간에서의 거리 자체가 "목표까지 얼마나 남았는가"를 알려주는 신호 역할을 합니다. TechCrunch는 이를 "AI가 행동하기 전에 먼저 생각하도록 만드는 모델"이라고 소개했습니다.
학습에는 두 가지 방식이 병행됩니다.
- 한 단계 예측: 현재 상태에서 바로 다음 상태를 예측. 안정적인 조건에서 정확한 동역학을 학습합니다.
- 다단계 예측: 모델이 자기 자신의 예측 결과를 입력으로 사용하여 여러 단계를 연쇄 예측. 이 과정이 없으면 멀리 내다볼수록 오차가 쌓여 불안정해집니다.
62시간의 데이터로 충분할까?
V-JEPA 2-AC(행동 조건부 모델)는 DROID 데이터셋의 비표지 로봇 비디오 62시간만으로 추가 학습되었습니다. 이후 학습에 전혀 포함되지 않은 새로운 실험실의 Franka Emika Panda 로봇 팔에 배치되어 제로샷으로 과제를 수행했습니다.
결과를 보면, 로봇 팔과 목표 위치 간 거리가 단계마다 줄어들며 x, y, z 축 모두에서 목표로 수렴합니다. 실패 사례도 의미적으로는 그럴듯한 경우가 많습니다. "유리잔 놓기"를 예측해야 할 상황에서 "병 놓기"를 예측하는 식인데, 동작의 종류는 맞추되 대상 물체를 혼동하는 패턴입니다. 모델이 행동의 의미 구조를 어느 정도 학습했음을 시사합니다.
V-JEPA 2 월드모델은 어떤 것이 가능할까?
비디오 이해: 이미지 모델과의 차이
V-JEPA 2 ViT-g(384)는 6개 벤치마크 평균 정확도 88.2를 기록합니다.
특히 흥미로운 지표는 시간 이해(SSv2) 성능입니다. 이미지 기반 인코더인 DINOv2(11억 파라미터)는 SSv2에서 50.7, SigLIP2(12억 파라미터)는 49.9에 머무는 반면, V-JEPA 2는 77.3을 기록합니다. 이미지 모델이 외양 기반 인식에서는 강하지만, "물체가 시간에 따라 어떻게 변하는가?"를 이해하는 데는 비디오 전용 모델과 큰 격차가 있다는 점이 확인됩니다.
같은 비디오 인코더인 InternVideo2(10억 파라미터, 평균 87.0)와 비교해도 V-JEPA 2(10억 파라미터, 평균 88.2)가 다소 앞서는 결과를 보여줍니다.
언어 없이 학습한 모델이 질의응답도 가능할까?
언어 없이 비디오만 보고 학습한 V-JEPA 2 인코더를 70억 파라미터 언어 모델과 연결했을 때, 비디오 질의응답 벤치마크 7개 평균에서 52.3을 달성합니다. DINOv2(45.7), SigLIP2(48.1), PE(49.1) 등 이미지 인코더 기반 방법들보다 높은 수치입니다.
이 결과가 시사하는 바가 있습니다. 언어 정보 없이 순수하게 비디오만 보고 학습한 표현이, 사후에 언어 모델과 연결되었을 때도 상당한 비디오 이해 능력을 발휘한다는 것은, JEPA 방식으로 학습된 표현이 풍부한 의미 정보를 담고 있을 가능성을 보여줍니다.
로봇 행동 계획: 초기 결과는 어떨까?
로봇 실험에서, 로봇 팔 끝과 목표 위치 간 거리가 단계가 진행될수록 일관되게 줄어듭니다. x, y, z 축 모두에서 목표로 수렴하며, 특정 과제에 대한 별도의 지도학습 없이 이 결과가 나왔다는 점이 주목할 만합니다.
실패 사례도 흥미로운 패턴을 보여줍니다. 예측이 틀리더라도 의미적으로는 그럴듯한 경우가 많습니다. "유리잔 놓기"를 예측해야 할 상황에서 "병 놓기"를 예측하는 식입니다. 동작의 종류는 맞추지만 대상 물체를 혼동하는 패턴인데, 이는 모델이 행동의 의미 구조를 어느 정도 학습했음을 시사합니다.
또한, 실험 결과에 따르면 V-JEPA 2는 NVIDIA Cosmos 대비 최대 30배 빠른 계획 속도를 보인다고도 합니다.(BigGo News, 2025).
JEPA 패러다임은 어디까지 확장되고 있을까?
V-JEPA 2 이후, JEPA의 "잠재 공간에서 의미를 예측한다"는 아이디어는 여러 방향으로 확장되고 있습니다.
VL-JEPA: 비전-언어로의 확장
2026년 ICLR에서 발표된 VL-JEPA는 JEPA를 비전-언어 과제로 확장한 모델입니다. 기존 비전-언어 모델(VLM)이 토큰을 자기회귀적으로 생성하는 방식이라면, VL-JEPA는 텍스트의 연속 임베딩을 예측합니다. 동일한 비전 인코더와 학습 데이터를 사용한 통제된 비교에서, 학습 가능 파라미터 50% 감소, 디코딩 연산 2.85배 감소를 달성하면서도 성능은 오히려 높았습니다(Chen et al., ICLR 2026). JEPA의 효율성이 비전을 넘어 언어 영역에서도 유효할 수 있음을 보여주는 결과입니다.
JEPA-VLA: 로봇 행동 모델로의 확장
2026년 2월에는 JEPA의 비디오 예측 능력을 로봇 행동 모델(VLA)에 접목한 JEPA-VLA가 발표되었습니다. 기존 VLA 모델이 낮은 샘플 효율과 제한된 일반화에 어려움을 겪는 문제를, JEPA의 예측적 표현 학습으로 보완하려는 시도입니다. LIBERO, RoboTwin 2.0 등 여러 벤치마크에서 기존 VLA 대비 의미 있는 성능 향상을 보고했습니다.
행동 계획의 개선: Value-guided JEPA
JEPA의 행동 계획 능력을 더 강화하려는 연구도 진행되고 있습니다. Sobal et al. (2026)은 잠재 공간의 거리가 목표까지의 가치 함수(value function)를 근사하도록 표현을 학습하는 방법을 제안하여, 기존 JEPA 대비 행동 계획 성능을 개선했습니다. V-JEPA 2의 잠재 공간 계획이 가진 한계(국소 최적에 빠질 수 있음)를 보완하려는 방향입니다.
이 연구가 제기하는 가능성과 남은 과제들
V-JEPA 2의 결과를 세 가지로 정리할 수 있습니다.
- 잠재 공간에서의 의미 예측이 효율적인 비디오 표현 학습 방법이 될 수 있다. 픽셀 복원 방식보다 적은 데이터로 경쟁력 있는 비디오 이해 성능을 달성했습니다.
- 인터넷 비디오를 통한 사전학습이 로봇 학습의 데이터 병목을 완화할 가능성이 있다. 100만 시간의 인터넷 비디오로 세상의 구조를 학습하고, 62시간의 로봇 데이터로 제로샷 제어에 성공했습니다.
- JEPA 패러다임이 비전, 비디오, 언어, 로봇 행동까지 확장되는 추세다. VL-JEPA, JEPA-VLA 등 후속 연구가 이 방향의 범용성을 탐색하고 있습니다.
하지만 동시에, 한계도 분명합니다.
- 로봇 제어 실험은 아직 팔 뻗기, 물체 잡기 수준의 비교적 단순한 과제에 한정되어 있습니다. 복잡한 도구 사용이나 다단계 조립은 미검증입니다.
- 물리 추론 벤치마크에서 인간과의 격차가 여전히 크다는 점은, "세상을 이해한다"는 표현이 아직 과장일 수 있음을 시사합니다.
- 한 행동당 약 16초의 계획 시간은 실시간 제어에는 부족하며, 실용적 배치를 위해서는 추가 최적화가 필요합니다.
- Malcolm Lett의 비평이 지적하듯, "JEPA가 혁명적이라기보다는 기존 자기지도학습의 자연스러운 다음 진화"라는 관점도 있습니다. 과도한 기대보다는 이 접근이 실제로 어디까지 확장 가능한지를 지켜보는 것이 적절할 것입니다.
더 넓은 시각에서 보면, 잠재 공간 예측(V-JEPA 2), 비디오 생성(Cosmos, Sora), 인터랙티브 환경 생성(Genie 3)이 각자의 방향에서 "AI가 물리 세계를 이해하는 방법"을 탐색하고 있습니다. 이들이 경쟁하는 관계인지, 아니면 결국 서로를 보완하며 결합되는 방향으로 갈 것인지는 앞으로 지켜볼 만한 흥미로운 질문입니다.
참고문헌
- Assran, M. et al. (2025). "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning." Meta. 논문 · GitHub · 블로그
- Assran, M. et al. (2023). "Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture." CVPR 2023
- Bardes, A. et al. (2024). "Revisiting Feature Prediction for Learning Visual Representations from Video." Meta Research
- He, K. et al. (2022). "Masked Autoencoders Are Scalable Vision Learners." CVPR 2022
- Chen, D. et al. (2026). "VL-JEPA: Joint Embedding Predictive Architecture for Vision-language." ICLR 2026
- JEPA-VLA (2026). "Video Predictive Embedding is Needed for VLA Models." arXiv
- Sobal, V. et al. (2026). "Value-guided action planning with JEPA world models." arXiv
- Meta (2025). IntPhys 2, MVPBench, CausalVQA 벤치마크. IntPhys 2 GitHub · CausalVQA GitHub
- NVIDIA (2025). Cosmos World Foundation Model Platform. NVIDIA Developer
- Google DeepMind (2025). "Genie 3: A New Frontier for World Models." DeepMind Blog