Tech
'관련 페이지 찾기'에서 '정확히 읽기'로: 기업 문서 AI를 위한 다음 단계

기업이 보유한 데이터의 80~90%는 비정형 데이터라고 합니다. IDC는 일찍이 2025년까지 전 세계 데이터의 80%가 비정형이 될 것으로 전망했고, 실제로 그렇게 됐습니다. PDF 보고서, 스캔 문서, 프레젠테이션 파일이 사내 곳곳에 쌓여 있지만, 이 데이터를 분석에 활용하고 있는 비율은 전체의 0.5%에 불과하다는 추정도 있습니다. 이 간극을 메우려는 시장의 움직임은 빠릅니다. MarketsandMarkets에 따르면 문서 AI 시장은 2025년 약 147억 달러에서 2030년 276억 달러로 성장이 전망됩니다. NVIDIA는 최근 기술 블로그에서 "기업 데이터는 본질적으로 멀티모달이며, 텍스트뿐 아니라 테이블, 차트, 다이어그램, 스캔 페이지를 아우르는 이해 능력이 필요하다"고 강조하기도 했습니다. 그런데 한 가지 의문이 생깁니다.
AI 기술이 이렇게 발전했는데, 왜 기업 문서를 여전히 제대로 읽어내지 못하는 걸까요?
전통적인 접근은 OCR로 문서에서 텍스트를 추출한 뒤, 그 텍스트를 검색하고 활용하는 방식이었습니다. 단순한 텍스트 문서라면 이걸로 충분합니다. 하지만 금융 보고서의 테이블 구조, 학술 논문의 수식, 기술 매뉴얼의 다이어그램은 텍스트만으로 설명되지 않습니다. Evolution AI의 분석에 따르면, 재무제표처럼 길고 복잡한 테이블이 포함된 문서에서 기존 OCR은 구조 정보를 잃어버려 정확한 데이터 추출이 어렵고, 이로 인한 오류가 비즈니스에 치명적일 수 있다고 합니다. 게다가 IntuitionLabs의 OCR 모델 비교 분석도 "VLM (Vision-Language Model)은 텍스트 추출과 동시에 문서 내용에 대한 추론이 필요할 때 탁월하다"고 평가하며, 전통 OCR에서 VLM 기반 접근으로의 전환을 조명했습니다.
"이미지 그대로 검색한다"는 발상의 전환: Visual RAG는 무엇일까?
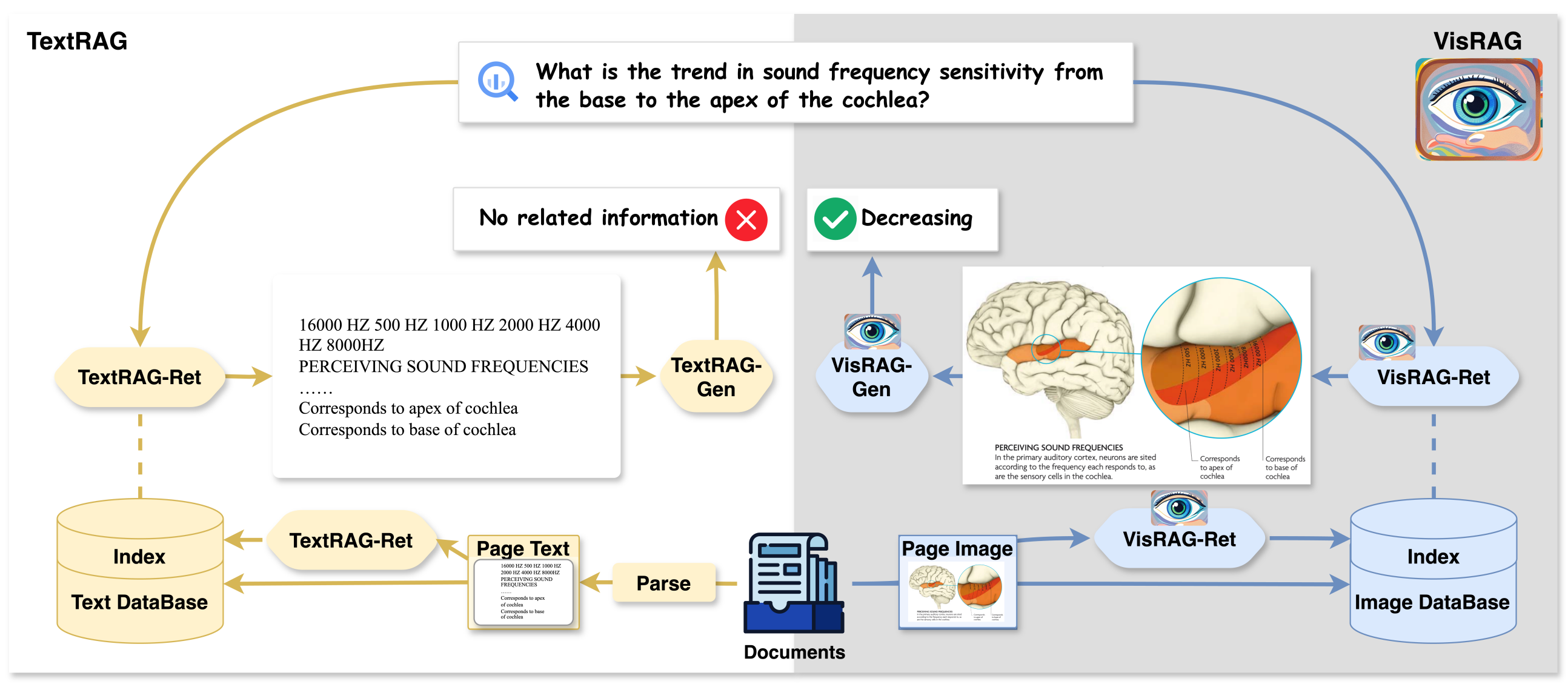
이 한계를 돌파하기 위해 등장한 것이 Visual RAG (시각 문서 검색)입니다. 기존 텍스트 기반 RAG가 문서에서 OCR로 텍스트를 뽑아낸 뒤 텍스트 조각을 검색하는 방식이었다면, Visual RAG는 문서 페이지 이미지 자체를 검색 단위로 사용합니다. OCR 파이프라인을 통째로 건너뛰고, 페이지 사진을 그대로 임베딩하여 검색하는 것이죠.
이러한 패러다임에 선도한 대표적인 연구는 ColPali(ICLR 2025)입니다. ColPali는 VLM을 활용해 페이지 이미지를 직접 벡터로 변환하는 검색 모델인데, 기존의 복잡한 OCR 기반 파이프라인을 대폭 간소화하면서도 검색 정확도는 오히려 크게 앞섰습니다. Hugging Face의 ColPali 블로그 포스트에서 저자들은 이를 비전 공간에서의 검색(Retrieval in Vision Space)이라는 새로운 개념으로 소개하며, 산업 현장의 문서 검색에도 높은 잠재력이 있다고 평가했습니다. Zilliz의 기술 블로그도 ColPali가 "텍스트뿐 아니라 시각 요소까지 기반으로 문서를 검색하는 방식을 근본적으로 바꿀 잠재력이 있다"고 분석했습니다. 이후 VisRAG(ICLR 2025)가 검색과 답변 생성을 통합하는 프레임워크를 제시하면서, Visual RAG는 하나의 연구 흐름으로 자리잡았습니다.
검색 단계는 분명 큰 진전을 이뤘습니다. 텍스트 질의로 이미지 문서를 찾아내는 것, 즉 서로 다른 모달리티를 연결하는 문제는 ColPali 이후 빠르게 발전해 왔습니다. 하지만 여기서 새로운 질문이 남습니다.
관련 페이지를 찾아오는 것만으로, 과연 문서를 제대로 이해했다고 말할 수 있을까요?
페이지를 찾는 것과 그 안에서 필요한 정보를 정확히 읽어내는 것은 전혀 다른 문제이기 때문입니다.
새로운 병목: "페이지를 찾았는데 왜 제대로 못 읽지?"
PDF 보고서에서 "2024년 3분기 총자산 증가액"을 묻는다고 합시다. Visual RAG 시스템은 관련 페이지를 정확하게 찾아옵니다. 하지만 그 페이지 이미지를 생성 모델에 통째로 넣는 순간, 두 가지 문제가 동시에 발생합니다.
첫째, 주의 분산 문제입니다. 한 페이지에는 핵심 재무제표 테이블뿐 아니라 회사 로고, 페이지 번호, 법적 고지사항, 관련 없는 다른 테이블이 함께 있습니다. 사람이라면 본능적으로 관련 테이블로 시선을 옮기겠지만, 모델은 이 모든 요소에 고르게 주의를 배분합니다. 정작 답이 있는 곳에 대한 집중도가 떨어지는 거죠.
둘째, 해상도 손실 문제입니다. 문서 페이지의 원본은 보통 2480x3508 픽셀 정도인데, 모델에 입력할 때는 시각 토큰 수의 제약으로 해상도가 크게 축소됩니다. 이 과정에서 8포인트 이하의 작은 글씨, 복잡한 테이블 셀 경계, 회전된 텍스트가 뭉개집니다. Microsoft의 ISE 개발자 블로그에서도 멀티모달 RAG 구축 시 "시각 요소의 세부 정보를 캡처하는 데 한계가 있다"는 점을 실무적 도전 과제로 지적한 바 있습니다.
이 문제가 얼마나 심각한지는 긴 문서 기반 시각 질의응답 성능을 평가하는 벤치마크인 MMLongBench-Doc(NeurIPS 2024)에서도 확인됩니다. 이 벤치마크는 사람 전문가의 정확도가 65.8 점이었지만, 같은 문서에 대해 당시 최고 성능 모델조차 이에 미치지 못했습니다. 특히 테이블과 차트처럼 세밀한 시각 정보가 핵심인 질문에서 격차가 두드러졌습니다.
결국 방향은 분명합니다. 페이지를 통째로 보는 방식에는 한계가 있고, 질의와 관련된 영역에만 선택적으로 집중하는 “세밀한 시각 인식”이 필요합니다. 그렇다면 모델은 필요한 정보에 어떻게 더 정확하게 집중할 수 있을까요? 최근 연구들은 이 질문에 서로 다른 방식으로 답하고 있습니다.
AgenticOCR: 잘 안 보이면 확대해서 읽자
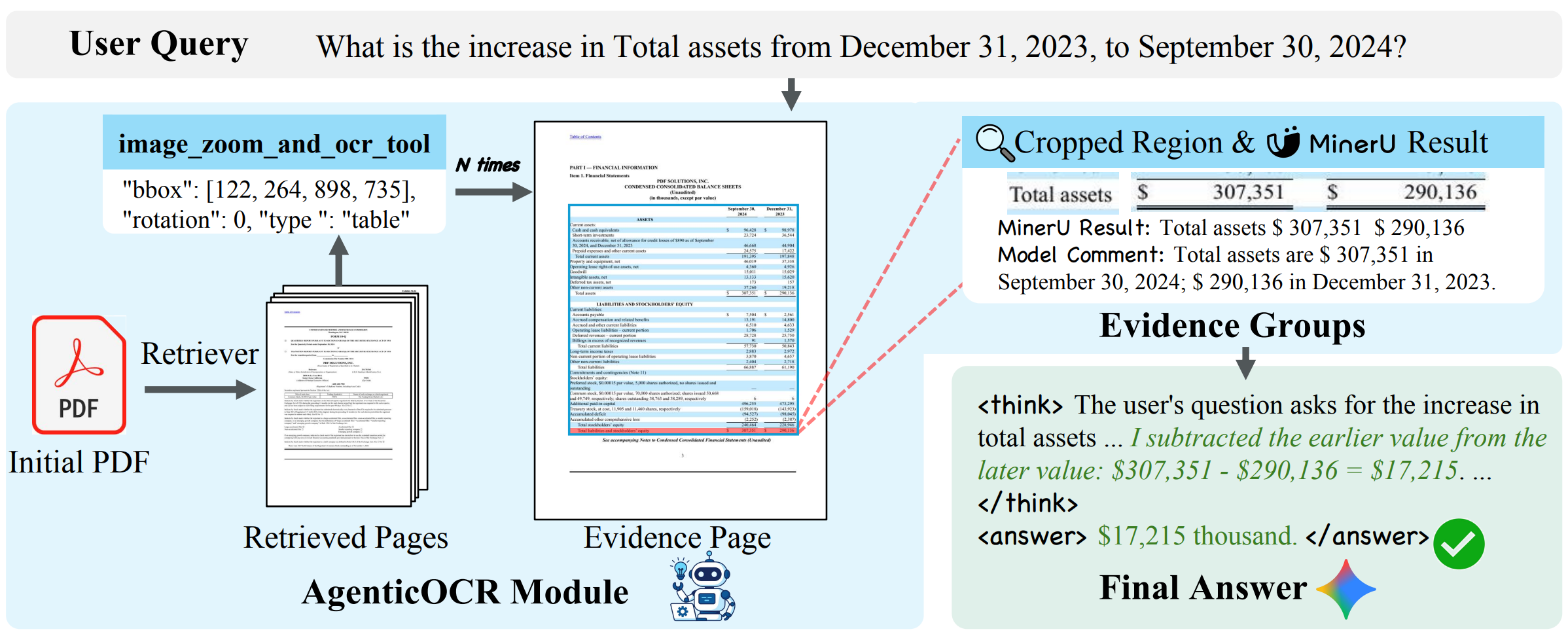
첫 번째 접근은 매우 직관적입니다. 문서를 읽다가 글씨가 너무 작거나 표가 복잡해서 한눈에 들어오지 않으면, 사람은 먼저 답이 있을 법한 부분을 가늠한 뒤 그 부분만 확대해서 다시 봅니다. AgenticOCR(arXiv, 2026)은 바로 이 과정을 문서 AI에 도입합니다. 핵심은 문서 전체를 한 번에 파싱하는 것이 아니라, 질문을 먼저 이해하고 그 질문에 필요한 부분만 골라 정밀하게 읽는 것입니다. 저자들은 이를 기존의 정적 OCR이 아니라, 질의를 기준으로 필요한 부분만 그때그때 추출하는 방식으로 정의합니다. 이 과정에서 AgenticOCR은 질문에 답하기 위해 어떤 영역을 어떤 방식으로 읽을지 스스로 결정합니다.
- 어디를 볼지(바운딩 박스 좌표)
- 어떻게 회전할지(0~270도)
- 어떤 세밀도로 파싱할지(영역 전체 분석 / 특정 요소만 인식 / 이미지만 자르기)
AgenticOCR은 "정확한 위치 찾기"를 어떻게 학습할까?
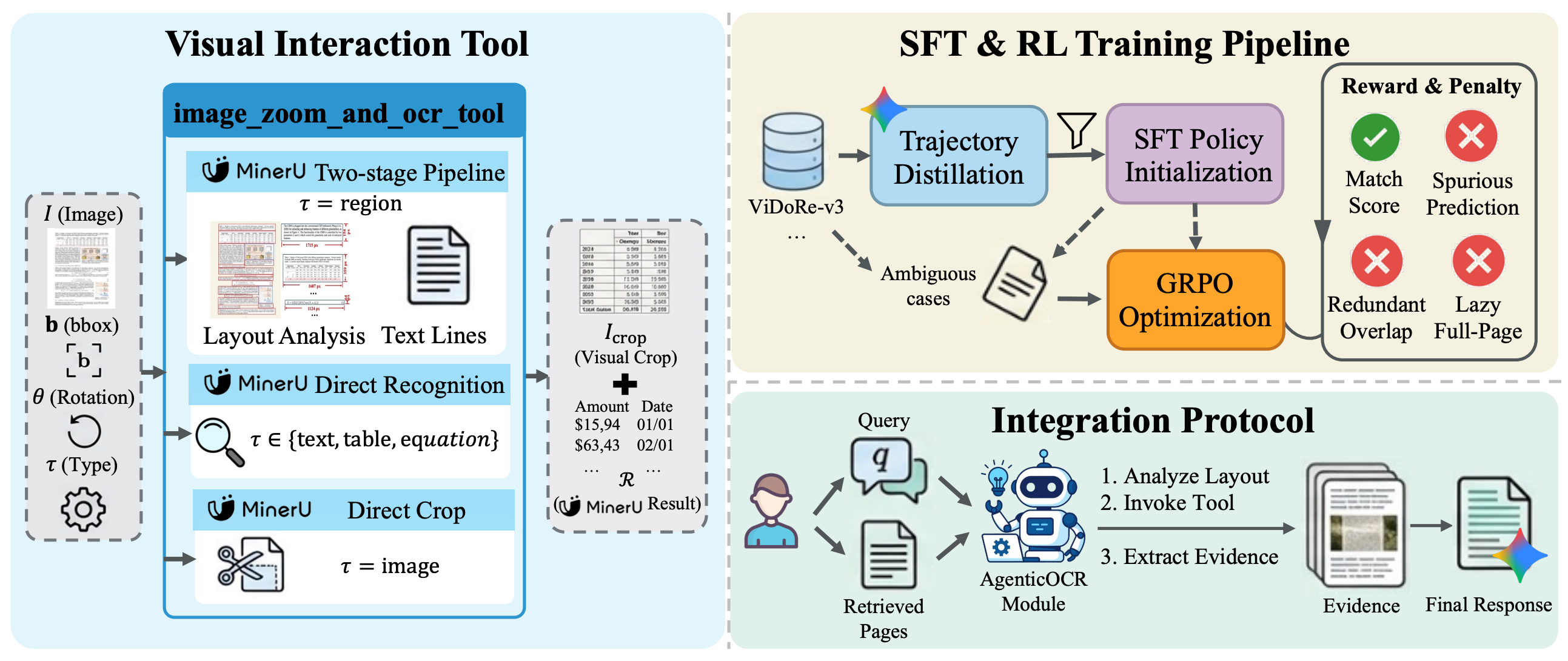
학습 방식도 이 철학에 맞춰 설계됩니다. 먼저 SFT 단계에서는 ViDoRe-v3의 질의, 페이지, 정답 박스 데이터를 바탕으로, Gemini-3-Pro-Preview가 남긴 고품질 도구 사용 궤적을 걸러 모방 학습합니다. 이 단계의 목적은 최종 답변을 잘 쓰게 만드는 것이 아니라, 언제 도구를 호출하고 어느 범위를 읽어야 하는지에 대한 기본 행동을 익히도록 학습하는 것이죠. 이후 GRPO 강화학습에서는 이 행동을 더 정교하게 다듬습니다. 보상은 최종 문장 자체보다 정답 영역을 얼마나 잘 찾았는지에 직접 연결됩니다. 정답 영역을 잘 포함하고 정확히 겹칠수록 보상을 받고, 관련 없는 박스를 예측하거나, 겹치는 박스를 여러 개 내놓거나, 페이지 대부분을 통째로 읽으려 하면 벌점을 받습니다. 정답이 없는 hard negative 페이지에서는 아예 박스를 내놓지 않아야 보상을 받도록 해, 읽지 말아야 할 페이지를 건너뛰는 능력까지 함께 학습합니다.
이렇게 학습된 AgenticOCR은 Visual RAG 파이프라인에서 검색기와 생성기 사이에 들어가는 중간 모듈로 동작합니다. 검색기가 찾아온 페이지를 그대로 생성 모델에 넘기는 대신, 답이 있을 만한 영역만 잘라 확대하고 OCR로 정밀 인식한 뒤 그 결과를 생성기에 전달하게되는 것이죠.
AgenticOCR의 성능은 어떨까?
MMLongBench-Doc에서 AgenticOCR-8B가 66.4점을 기록하여 사람 전문가(65.8점)를 넘었습니다. 금융 도메인 특화 벤치마크인 FinRAGBench-V(EMNLP 2025)에서는 78.6점으로 기존 방법들을 크게 앞질렀습니다. 빽빽한 금융 보고서에서 확대/자르기의 효과가 극대화된 결과입니다.
다만 한계도 분명합니다. 특정 영역만 잘라 읽으면 필요한 정보는 더 또렷하게 포착할 수 있지만, 그 바깥의 문맥 또한 함께 사라질 수 있습니다. 예를 들어 표의 특정 숫자 값만 확대하면, 그 숫자가 무엇을 뜻하는지 설명하는 헤더 정보가 잘려 나갈 수 있는 것이죠. 즉, AgenticOCR은 정밀도를 높이는 데 효과적이지만, 그만큼 맥락 보존에서는 제약을 안습니다.
Lang2Act: 자르지 말고, 더 주의깊게 보자
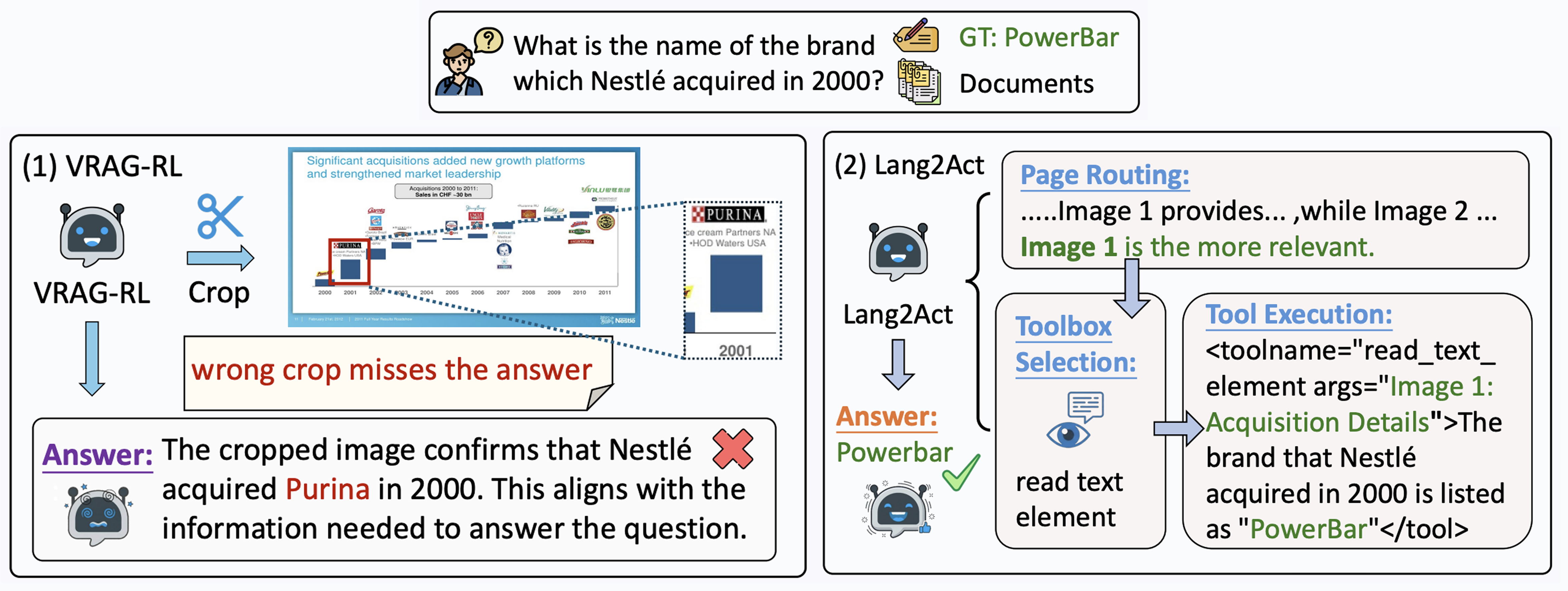
Lang2Act(ACL 2026 Findings)는 먼저 앞서 본 AgenticOCR식 접근, 즉 질의와 관련된 영역만 잘라 확대해 읽는 방식의 한계를 짚습니다. 필요한 영역만 잘라내면 작은 글씨나 세부 패턴은 더 또렷하게 볼 수 있지만, 그 과정에서 경계 바깥 정보와 시각 요소 사이의 연결이 함께 사라질 수 있다는 것 입니다. 특히 문서 이해에서는 표의 헤더와 값, 차트의 범례와 본문처럼 떨어져 있는 요소를 함께 봐야 의미가 완성되는 경우가 많기 때문에, 특정 영역을 잘라내기는 정밀도를 높이는 대신 주변 맥락을 함께 잃을 수 있는 것이죠.
핵심 아이디어: 외부 도구 대신 언어적 도구로 집중을 유도한다
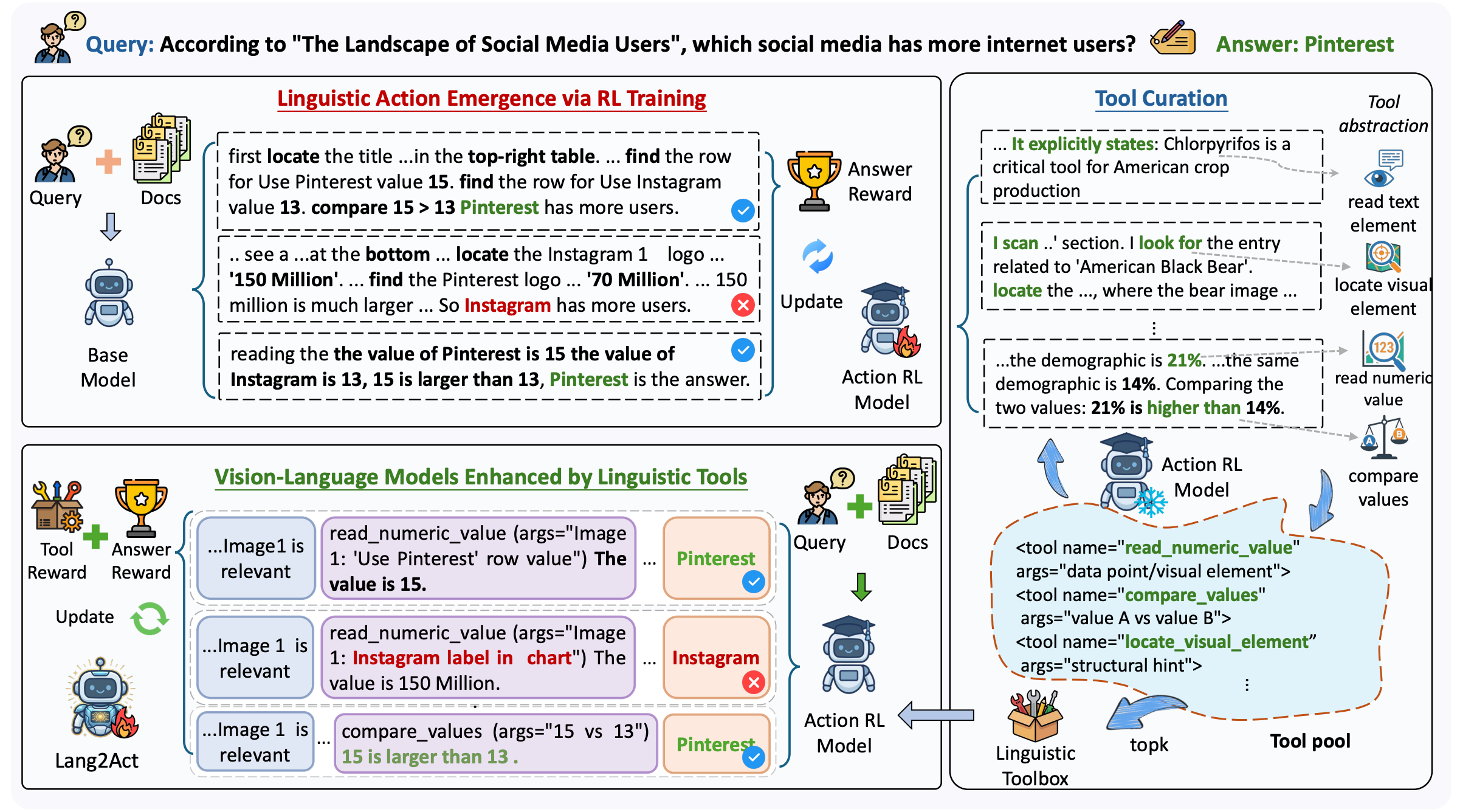
Lang2Act의 해법은 외부 이미지 도구를 더 정교하게 쓰는 것이 아니라, 모델 내부의 주의를 언어적으로 조절하는 것입니다. 구체적으로는 *read_text_elem*, *read_numeric_value*, *locate_visual_element* 같은 특수 토큰을 추론 과정에서 직접 생성하게 하고, 이 토큰이 해당 시각 정보에 대한 주의를 유도하도록 설계합니다. 즉, 외부 OCR 도구로 이미지를 물리적으로 조작하는 대신, 페이지 전체를 유지한 채 모델이 스스로 어떤 정보를 읽고 비교할지를 텍스트 토큰으로 드러내는 방식입니다. 논문은 이런 linguistic tools가 고정된 외부 엔진이 아니라, 모델의 자기회귀적 생성 과정 안에서 작동하는 내부적 행동 형식이라고 설명합니다.
학습 방식도 AgenticOCR와 다릅니다. Lang2Act는 바운딩 박스 정답을 직접 주지 않고, 2단계 강화학습을 통해 문제 해결에 유용한 시각 행동이 자연스럽게 나타나도록 만듭니다. 먼저 모델이 스스로 효과적인 visual actions를 탐색하게 하고, 그 과정에서 반복적으로 등장한 행동들을 linguistic tool pool로 수집합니다. 이후 이 도구들을 정리해 다시 추론에 활용하도록 최적화를 수행하며, 최종적으로는 상위 7개 도구만으로 전체 도구 사용의 98.9%를 커버했다고 보고합니다. 즉, “어디를 봐야 하는가”를 명시적으로 가르치기보다, 잘 푸는 추론 궤적 속에서 시각 행동이 발현되도록 유도하는 설계인 것이죠.
성능과 한계: 더 잘 보는 방식은 어디까지 유효한가
실험 결과는 Lang2Act의 성능 향상이 단순히 추론을 길게 만든 결과가 아니라, 실제로 시각적 근거를 더 잘 포착한 데서 비롯되었음을 보여줍니다. 세 벤치마크 평균에서 63.39를 기록해 모든 비교군들 보다 앞섰고, 정답 문서가 보장되는 oracle retrieval 설정에서도 평균 67.63으로 가장 높은 성능을 보여줍니다. 저자들은 여기에 더해 perception rate, 즉 모델의 내부 주의가 실제 정답 영역을 얼마나 바라보는지를 분석했는데, 이 비율과 QA 정확도 사이에 강한 양의 상관관계가 나타났으며 두 지표 모두에서 가장 높은 수준을 보였습니다. 다시 말해, 이 모델은 더 잘 추론해서가 아니라 더 잘 봐서 성능이 오른 것임을 강력히 입증해냈습니다.
다만 한계도 분명합니다. Lang2Act는 페이지 전체 맥락을 유지한다는 점에서는 강하지만, 해상도 자체를 물리적으로 높여주는 방식은 아닙니다. 즉, 어디를 봐야 하는지는 더 잘 알게 해주지만, 잘 보이지 않는 정보를 새롭게 선명하게 만들어 주지는 못합니다. 따라서 정보가 빽빽하게 들어찬 표나 작은 글씨, 미세한 셀 경계처럼 실제로 확대해 봐야 하는 문서에서는, 필요한 영역을 잘라 정밀하게 읽는 방식이 여전히 더 유리할 수 있습니다.
실무에서는 어떤 접근이 더 유리할까?
두 접근의 차이는 결국 무엇을 더 우선시하느냐로 정리할 수 있습니다. AgenticOCR은 질의와 관련된 영역을 물리적으로 잘라 확대해 읽기 때문에, 더 많은 픽셀을 보며 정보를 정밀하게 복원하는 데 강점이 있습니다. 반면 Lang2Act는 페이지 전체를 유지한 채 모델의 주의를 조절하므로, 요소들 사이의 관계와 배치를 함께 살피는 맥락 보존에 유리합니다. 다시 말해, 하나는 fidelity를 높이는 방식이고, 다른 하나는 retention을 지키는 방식이라고 볼 수 있습니다.
이 차이는 문서의 성격에 따라 실무적인 선택 기준으로 이어집니다. 빽빽한 금융 보고서, 법률 문서, 기술 사양서처럼 작은 글씨와 복잡한 표가 많고, 특정 수치나 조항을 정확히 읽어내는 것이 핵심인 문서에서는 AgenticOCR 쪽이 더 유리합니다. 이런 문서에서는 주변 맥락을 조금 덜 보더라도, 필요한 부분을 확대해 선명하게 읽는 것이 더 큰 가치를 가지기 때문입니다. 반대로 슬라이드, 인포그래픽, 일반 보고서처럼 넓은 레이아웃 위에 제목, 도표, 범례, 캡션, 본문이 흩어져 있고, 이들 사이의 관계를 함께 해석해야 하는 문서에서는 Lang2Act가 더 적합합니다. 이 경우 중요한 것은 한 부분을 확대하는 것보다, 페이지 전체 맥락 속에서 여러 시각 요소를 연결해 이해하는 능력이죠.
운영 관점에서도 두 접근의 성격은 분명히 갈립니다. AgenticOCR은 검색기와 생성기 사이에 들어가는 모듈형 구조이기 때문에, 뒤에 붙는 생성 모델을 비교적 자유롭게 교체할 수 있습니다. 더 좋은 성능을 내는 생성기가 출시되면 전체 시스템을 다시 설계하지 않고도 곧바로 연결해 성능 향상을 기대할 수 있을 것입니다. 반면 Lang2Act는 인식과 추론, 답변 생성을 하나의 모델 내부에서 처리하는 일체형 구조에 가깝습니다. 파이프라인은 더 간결하지만, 기반 모델을 바꾸려면 추론 방식 자체를 다시 학습해야 할 가능성이 큽니다. 결국 실무에서는 "어떤 문서를 다루는가"와 함께 "얼마나 유연하게 시스템을 교체·확장해야 하는가"까지 함께 고려해야 합니다.
마무리
문서 AI가 자동화하는 범위는 빠르게 넓어지고 있습니다. 결국 기업 문서 AI의 다음 승부처는 얼마나 큰 모델을 쓰느냐보다, 같은 모델에게 어떻게 읽게 만드느냐에 더 가까워 보입니다. 페이지 전체를 무작정 처리하게 두는 대신, 필요한 곳에 시선을 모으고, 상황에 따라 확대하거나 맥락을 유지한 채 추론하도록 설계하는 능력이 실제 성능 차이를 만들기 시작한 것입니다. 이 질문에 먼저 답하는 쪽이, 기업 안에 쌓여 있는 방대한 비정형 데이터 80%를 실제 활용 가능한 자산으로 바꿀 수 있느냐를 판가름할 것입니다.
참고문헌
- https://venturebeat.com/data-infrastructure/report-80-of-global-datasphere-will-be-unstructured-by-2025
- https://deep-talk.medium.com/80-of-the-worlds-data-is-unstructured-7278e2ba6b73
- https://www.marketsandmarkets.com/Market-Reports/document-ai-market-195513136.html
- https://developer.nvidia.com/blog/build-ai-ready-knowledge-systems-using-5-essential-multimodal-rag-capabilities
- https://www.evolution.ai/post/financial-statement-extraction
- https://intuitionlabs.ai/articles/ai-ocr-models-pdf-structured-text-comparison
- https://arxiv.org/abs/2407.01449
- https://huggingface.co/blog/manu/colpali
- https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy
- https://arxiv.org/abs/2410.10594
- https://devblogs.microsoft.com/ise/multimodal-rag-with-vision/
- https://arxiv.org/abs/2407.01523
- https://arxiv.org/abs/2602.24134
- https://arxiv.org/abs/2505.17471