Tech
초개인화 시대의 AI모델 정렬을 위한 개인화 보상모델링


AI를 통한 초개인화(hyper-personalization) 경험 생성
최근 생성형 AI 기술의 발전으로 모델이 사용자 맞춤형 답변·요약·계획·콘텐츠 등 다양한 개인화 경험을 거의 실시간으로 생성할 수 있게 되면서, AI 기반 시스템도 개별 사용자의 요구를 더 정교하게 충족하는 방향으로 빠르게 진화하고 있습니다.
이러한 발전으로 초개인화(hyper-personalization) 시대, 즉 개별 사용자 행동에 즉각적으로 반응하는 시스템을 통해 고도로 맞춤화된 경험을 제공하는 시대가 열리고 있지만, 그만큼 사용자가 기대하는 개인화의 수준도 더 다양해지고 더 까다로워져, “개인화 경험의 만족도”에 대한 기준 자체가 빠르게 높아지고 있습니다.
이러한 변화는 실제 통계에서도 드러나고 있습니다.
- McKinsey는 소비자의 71%가 개인화된 상호작용을 기대하고, 76%가 개인화가 제공되지 않을 경우 불만을 느낀다고 보고합니다.
- 또한 성장 속도가 빠른 조직일수록 개인화에서 발생하는 매출 기여가 더 크며, 빠른 성장 조직이 느린 성장 조직보다 개인화로부터 40% 더 많은 매출을 만든다고 분석합니다.
- 마케팅의 측면에서 봤을때, “소비자는 개인화가 되는 브랜드를 더 선호한다”는 신호도 강합니다. Accenture는 소비자 91%가 ‘나를 기억/이해하고 관련 추천을 주는 브랜드’에서 더 쇼핑할 가능성이 높다고 보고합니다.
그런데 중요한 건, 시스템의 발전 대비 사용자가 체감하는 개인화의 품질은 아직 모자라다는 점입니다. Deloitte Digital은 소비자가 자신의 경험 중 43%만 ‘개인화됐다’고 인식하는 반면, 브랜드는 자사 사용자 경험의 개인화 수준을 평균 61%로 평가한다고 보고됩니다.
이런 체감의 간극이 커질수록 자연스럽게 한 가지 질문이 생깁니다.
“개인화는 분명 고도화되고 있는데, 왜 체감 사용자 경험은 그렇지 않을까?”
초개인화를 위한 AI 에이전트의 정렬문제

전통적 개인화의 목표: ‘후보 노출’ 최적화
기존의 추천시스템과 같은 대표적인 개인화 AI 시스템은 주로 다음과 같은 전제를 깔고 있었습니다.
- 고정된 후보(item set)가 있고
- 시스템의 목표와 행위(action)는 주로 “무엇을 어떤 순서로 노출할지(랭킹/정렬)”와 같이 제한적이며
- 클릭/구매/체류시간 같은 관측 가능한 사용자 선택을 목표 신호로 모델을 최적화한다
이러한 설정에선 “어떤 아이템을 먼저 노출시켰을때 사용자 클릭이 늘었다” 와 같은 형태처럼 모델에게 가르칠 “정답”이 비교적 단순합니다.
에이전트형 개인화의 목표: ‘과정 전체’의 정렬
하지만 최근 대규모 언어모델(LLM) 기반 AI 시스템이 단편적 응답 생성을 넘어 사용자와의 지속적 상호작용과 과업수행을 전제로 한 에이전트 형태로 확장되면서, 사용자가 체감하는 개인화의 의미또한 크게 변화하고 있습니다.
이제 시스템이 해야할 일은 단순히 후보를 노출하는 수준을 넘어서,
- 사용자 질의를 해석하고
- 필요한 정보를 획득/요약/정리하고
- 이전의 사용자 경험을 기억하며
- 때로는 되묻고 계획을 업데이트하는
장기 지평(long-horizon)의 다단계 상호작용으로 확장되며 이 과정 전체가 사용자 경험을 결정합니다.
이처럼 과정 전체의 조율을 목표로 하는 시스템은 더이상 목표를 달성하기 위한 “정답 경로”가 하나로 고정되지 않습니다. 그래서 각 시점의 바람직한 다음 행동을 지도학습(supervised learning)이 가능하도록 단일 정답(label)로 정의하기가 어렵고, 결과적으로 개인화된 AI시스템의 핵심 과제는 다음과 같이 전환됩니다:
“사용자가 무엇을 선택할까”를 맞추는 문제 →
사용자 의도에 부합하는 ‘상호작용의 방향/진행 방식’을 어떻게 정의하고, 그에 따라 시스템을 일관되게 유도할 것인가
이러한 관점이 바로 개인화 정렬(personalized alignment) 입니다.
그렇다면 이런 개인화 정렬을 위해 시스템은 매 순간 여러 선택지 중 하나를 골라 다음 행동을 해야 하는데 이때 시스템이 “이 사용자에게 무엇이 더 좋은 행동/응답인가”를 판단할 기준을 어떻게 설정할 수 있을까요?
개인화 정렬의 핵심: 보상모델링
에이전트가 “다음 행동”을 고르려면, 결국 매 순간 이렇게 판단해야 합니다.
“지금 이 행동/응답이 이 사용자에게 얼마나 만족스러운가?”
하지만 사용자 만족은 직접 보이지 않습니다. 시스템이 관측할 수 있는건 대부분 사용자의 온전한 선호 그 자체가 아니라 피드백을 통해 부분적으로 드러나는 대리 신호(proxy) 뿐입니다.
- 클릭/체류시간/재방문 같은 사용자의 행동 로그를 통한 암묵적 피드백
- 평점, A/B 선호, 코멘트 같은 사용자의 명시적 피드백
그래서 개인화 정렬에서 핵심은 이런 대리 신호로부터 ‘만족’이라는 목표를 시스템이 학습 가능한 형태로 구성해주는 것이되고, 이때 가장 표준적인 방식이 보상모델링(reward modeling) 입니다.
- 보상모델링: (맥락, 후보 행동/응답)을 입력으로 받아 “얼마나 바람직한가”를 점수(보상) 또는 선호 판정(A가 B보다 낫다) 형태로 예측하는 점수 예측기/판별기를 학습한다.
- 개인화 보상모델링: 여기에 사용자 히스토리/프로필/현재 상태를 조건으로 넣어서, “개별 사용자에게 더 좋은 행동/응답”을 같은 방식으로 점수화/판정한다.
즉, 개인화 정렬을 위한 보상모델링의 목표는 관측 가능한 신호로부터 시스템의 행동에 대한 사용자의 만족도를 추정하고, 이 만족도를 시스템이 학습가능한 신호로 제공하는 것에 있습니다.
그렇다면 이 “기준”을 모델 안에서 어떤 형태로 표현하고, 사용자마다/상황마다 달라지는 기준을 어떻게 학습시키는 게 좋을까요?
개인화 보상모델링 연구 흐름
초기접근: 사용자 선호기준을 정해진 선호축 안에서 각 축을 얼마나 혼합할지로 표현하자
초기의 개인화 보상모델링을 통한 모델의 정렬은 보통 이런 발상에서 출발했습니다.
- “좋은 응답”을 몇 개의 고정된 평가 축으로 나눈다 (예: 더 정확한가 / 더 친절한가 / 더 간결한가)
- 사용자마다 그 축의 가중치를 다르게 두면 개인화가 된다 (예: A 사용자는 0.7만큼의 정확성 과 0.3만큼의 친절함을 원함)
장점은 분명합니다. 해석이 쉽고, 구현도 비교적 단순합니다.
하지만 실제 사용자 데이터를 다루면서 다음과 같은 문제들이 자연스럽게 생겨납니다.
- 사용자의 선호는 축 몇 개로 깔끔히 정리되기 어렵고
- 상황에 따라 기준이 바뀌고(오늘은 “짧게”, 내일은 “근거까지”)
- 심지어 “축에 없는 기준”으로 선호판단을 합니다(예: 정리 방식, 질문을 얼마나 되묻는지)
그래서 개인화 보상모델링의 핵심 질문도 이렇게 바뀝니다.
“정해져있는 선호축의 가중치를 어떻게 조절할까?”가 아니라
“사용자가 지금 중요하게 보는 기준 자체를 어떻게 잡아낼까?”
이런 문제의식을 최근 공개된 관련 연구를 통해 좀 더 자세히 살펴보겠습니다.
“P-Check: Advancing Personalized Reward Model via Learning to Generate Dynamic Checklist”, [arXiv]
P-Check: 사용자의 선호기준을 어떻게 모델링했을까?
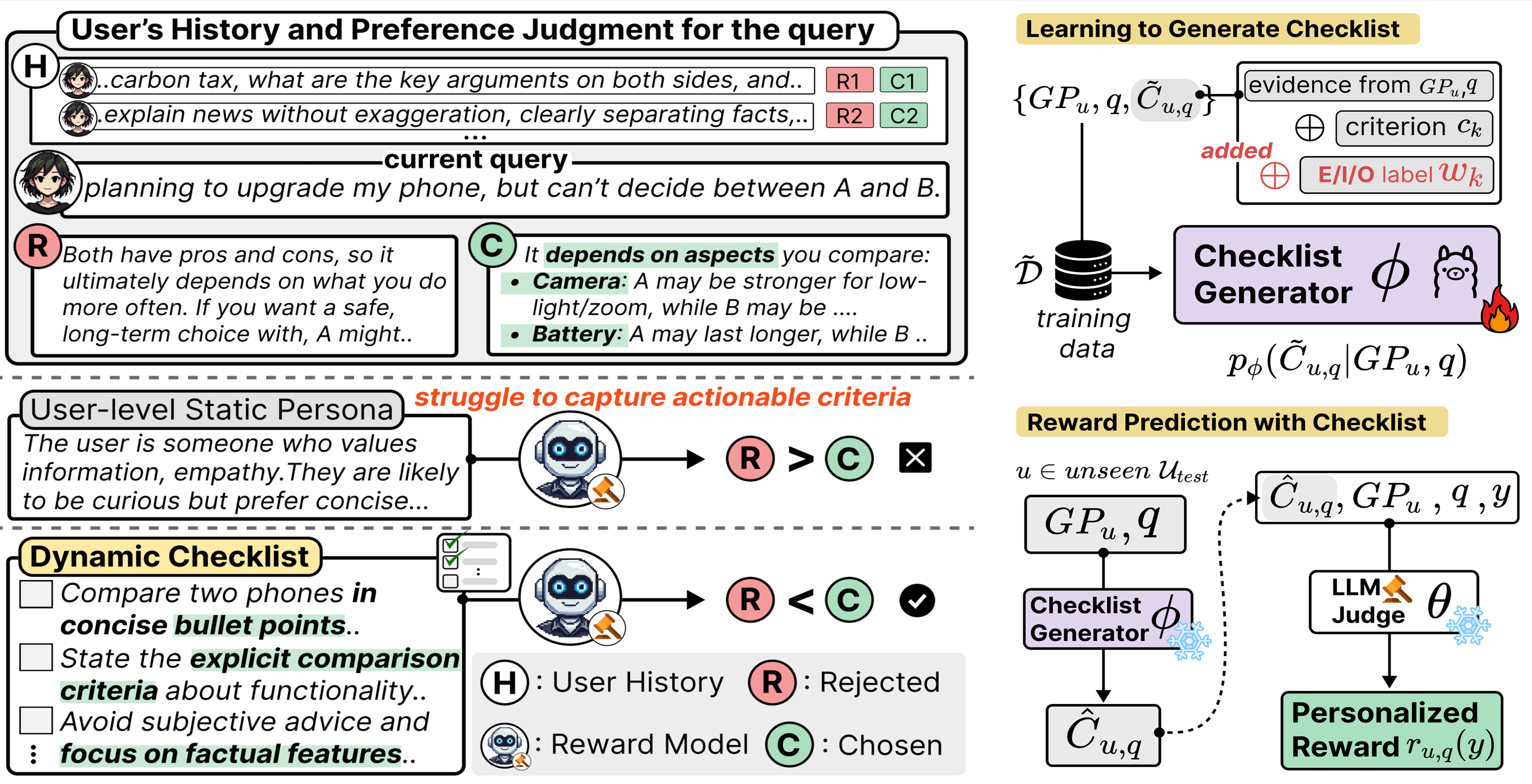
P-Check의 핵심 아이디어는 한 줄로 말하면 다음과 같이 정리할 수 있습니다.
개인화는 사용자에 맞게 “어떤 축을 얼마나 섞을지”라는 문제를 넘어,
사용자 이력으로부터 ‘평가 기준(체크리스트)’ 자체를 만들어내는 문제로 확장된다.
즉, P-Check는 보상을 바로 예측하기 전에 '이 사용자라면 이 응답을 어떻게 평가했을까?' 에 대한 ‘기준’을 먼저 생성하고, 그 기준으로 후보 응답을 평가해 최종 보상 점수를 예측합니다.
보상모델이 사용자의 평가기준을 어떻게 예측했을까?
레시피 1) 사용자 히스토리에서 “선호 단서”를 요약한다
개인화의 출발점은 “이 사용자는 어떤 스타일을 좋아하나”를 잡아내는 겁니다.
이를 위해 P-Check는 과거 대화/피드백/선호 표현에서 반복되는 패턴을 요약해 사용자 상태(요약 프로필)를 만듭니다.
- 입력: 사용자 히스토리(대화, 피드백 로그 등)
- 출력: 선호 요약(예: 근거 중심, 구조화 선호, 길이/톤, 검증 요구 등)
여기서 중요한 포인트는, 이 요약이 “고정된 사용자 프로파일”이 아니라 현재까지의 상호작용을 반영한 상태라는 점입니다.
레시피 2) 현재 요청을 보고, “이번에 필요한 기준”을 뽑는다
P-Check는 고정 축으로 사용자 선호를 제한하지 않고, 이번 요청에서 중요할 법한 기준을 체크리스트 형태로 생성합니다.
예를 들어 같은 사용자라도 과업(task)이 바뀌면 기준이 달라지는 게 자연스럽습니다.
- “논문 요약”이면: 정확성, 구조화, 핵심 주장–근거 매핑, 누락 방지
- “여행 계획”이면: 예산 제약, 동선, 대안 플랜, 위험/변수 안내
즉, P-Check는 “사용자 선호”를 항상 같은 축에서 재현하려 하지 않고, 사용자 요청 단위로 기준을 재구성합니다.
레시피 3) 후보 응답을 체크리스트 기준으로 항목별로 평가한다
보상모델이 바로 “A가 더 좋다/점수 0.83”을 내는 대신, 먼저 체크리스트 항목별로 판단을 만듭니다.
- 기준1에서는 A가 더 낫고
- 기준2에서는 B가 더 낫고
- 기준3에서는 둘 다 애매하고
이 단계를 거치면 개인화는 단순히 “보상점수를 맞추는 것”을 넘어, 어떤 기준에서 무엇이 부족했는지를 구체적으로 드러낼 수 있게 됩니다.
레시피 4) 기준별 중요도를 반영해 최종 점수/선호 판정을 만든다
모든 기준이 항상 똑같이 중요한 건 아닙니다. 그리고 어떤 기준은 사용자의 선호를 잘 가르지만 어떤 기준은 잡음이 될 수도 있습니다.
P-Check는 이런 문제를 정면으로 다룹니다. 사용자 선호를 더 잘 구분해주는 기준일수록 더 큰 비중을 주는 방식 체크리스트 생성모델을 학습하고, 기준별 판단을 합쳐 최종 보상점수를 출력합니다.
체크리스트는 “진짜로” 개인화에 도움이 됐을까?
그렇다면, 체크리스트를 통한 개인화 보상모델링이 실제로 개인화 성능을 높였을까요?
논문 결과는 꽤 명확합니다. 보상 예측 정확도부터 개인화 생성 품질까지, 전반적으로 개선이 확인됩니다.
흥미로운 발견
1) 개인화된 체크리스트 기반 보상 모델링이 ID/OOD 모두에서 일관된 상승을 보인다.
가장 기본적인 평가인 “선호쌍에서 어떤 응답을 더 좋아할지 맞추는가?”에서, P-Check는 기본 LLM-judge 대비 평균 정확도를 53.19% → 63.62%로 끌어올립니다.
특히 분포가 다른 OOD(out-of-distribution) 환경에서도 좋은 성능을 내며 일반화 능력에서 강점을 보입니다. 예를 들어 BESPOKE-MetaEval(OOD) 벤치마크에서는 Llama3-8B judge 기준 55.46% → 75.48%로 성능이 크게 향상되는 결과를 보여줍니다.
2) 작은 체크리스트 생성기(3B)가 큰 LLM-Judge의 보상예측 정확도를 향상 시킨다.
인상적인 포인트는, P-Check가 특정 모델에서만 작동하는 제한적인 트릭이 아니라는 점입니다.
Qwen, GPT 등 더 많은 파라미터를 가진 다양한 LLM-judge에 붙여도 일관된 성능향상을 보여줍니다. 즉 무엇을 평가해야 하는지(기준)를 잘 주면 작은 체크리스트 생성기 만으로도 큰 보상모델이 더 정확해진다는 겁니다.
3) 체크리스트 기반 개인화 보상모델을 “정렬에 실제로” 쓰면 개인화 응답 품질이 향상된다.
앞서 보상모델은 결국 모델의 정렬을 위해 사용된다고 말씀드렸듯, 논문은 P-Check를 실제 정렬에 사용했을때 생성 품질도 같이 좋아지는지까지 확인합니다.
저자들은 실제로 P-Check이 예측한 보상이 정책모델의 정렬을 향상시킨다는 결과를 Best-of-N, DPO(Direct Preference Optimization) 두가지 모델 정렬방법을 통해서 보여줍니다.
4) “히스토리가 적은 사용자”에서도 상대적으로 더 강건한 성능을 보인다.
연구를 위한 벤치마크 세팅을 넘어서, 개인화 시스템이 현실에서 동작할때 자주 발생하는 문제중 하나는 선호를 추정할 수 있을 만큼 상호작용이 풍부한 유저가 많지 않다는 점입니다. 하지만 P-Check은 이런 long-tail 유저 데이터에서도 상대적으로 안정적인 성능을 보여줍니다.
기업의 개인화 서비스 설계에서의 적용 전략

개인화 AI서비스를 운영하는 기업에게 P-Check의 접근은 소비자 대상 개인화 서비스를 설계할 때, “사용자 정보를 넣는다” 수준을 넘어 개인화 기준을 운영하는 구조를 만들 수 있다는 점에서 참고할 만합니다.
실제 개인화 서비스의 운영에서는 "사람마다 다른 만족 기준을 어떻게 안정적으로 반영할 것인가", 그리고 그 기준을 "시스템이 운영되는 환경 내에서 지속적으로 업데이트할 수 있는가"가 성패를 가릅니다. P-Check의 접근이 의미 있는 이유도 여기에 있습니다. 개인화를 사용자 요청마다 필요한 평가 기준을 만들고 그 기준으로 생성/판단을 운영하는 방식으로 접근하기 때문입니다.
개인화 서비스를 만드는 기업이라면, 제품 설계 단계에서 사용자 선호를 “저장 가능한 상태”로 정리해두는 구조를 먼저 고려해볼 만합니다. 대화·클릭·저장·수정 같은 행동 로그와 명시적 피드백을 모아, “이 사용자가 무엇을 중요하게 보는지”를 가볍게 요약해두면 이후 요청 처리에서 일관성이 생깁니다. 또 매 요청 시점에는 그 상태와 현재 질문을 함께 참고해, 이번 응답에서 지켜야 할 기준을 짧은 체크리스트 형태로 먼저 구성해보는 접근이 가능합니다. 그리고 생성된 응답을 그 기준으로 한 번 점검·보완하는 루프를 기본 동작으로 넣어두면, 개인화를 반복해서 개선 가능한 품질 관리 대상으로 만들 수 있습니다.
특히 서비스의 지속성 측면에서 중요한 포인트는 사용자 피드백 신호의 품질을 끌어올리는 장치와 환경을 같이 만드는 겁니다. 예를 들어 유저가 시스템 응답에 대한 피드백으로 “무엇이 좋았는지/무엇이 부족했는지”에 대한 평가를 구체적인 항목 단위로 남기게 하거나, "A/B 응답 중 무엇이 더 나은지" 선택하게 하면 학습 신호가 훨씬 선명해집니다. 즉, 이런 입력을 자연스럽게 남기게 만드는 제품 내 피드백 UX의 효과적인 설계가 곧 개인화 정렬을 지속가능하게하는 인프라가 됩니다.
마무리하며
초개인화의 확산과 에이전트형 AI의 등장은 이제 거스를 수 없는 흐름이 되었습니다. 사용자는 더 이상 개인화를 “내 취향에 맞는 상품을 잘 골라서 보여주는 것”에 만족하지 않고, "나의 상황과 기준에 맞춰서 계획하고 정리하고 실행해주는 경험"을 기대합니다. 그리고 그 기대가 커질수록, 개인화는 단순히 사용자 정보를 더 넣는 문제가 아니라 "무엇을 좋은 응답으로 볼지에 대한 기준을 어떻게 세울지"의 문제로 자연스럽게 이동합니다.
오늘 우리는 그 흐름 속에서, 보상모델링이 사용자 피드백을 학습 가능한 신호로 만들고, 평가 기준(체크리스트)을 구성해 응답을 평가하는 방식이 어떻게 개인화 정렬을 구체화하는지 살펴봤습니다.
그렇다면 머지않은 미래, 개인화 AI가 더 많은 의사결정과 행동을 대신하게 되는 시대에는 어떤 기업이 앞서가게 될까요? 모델 크기에 따른 지식의 증가가 아니라, 기준을 만들고, 점검하고, 피드백으로 업데이트하는 사이클을 제품 안에 안정적으로 심은 팀이 결국 더 빠르게 개인화 정렬을 고도화할 가능성이 큽니다.
따라서 앞으로도 관련 기술 흐름을 꾸준히 지켜보며, 이를 제품에 자연스럽게 녹여내는 기업이 초개인화 시대의 핵심 경쟁력을 확보할 수 있을 것입니다.