AI Insight
AI 연구 자동화는 어디까지 왔을까? autoresearch와 AI Scientist로 보는 현재와 한계

ML 연구자라면 이 루틴이 익숙할 겁니다. 코드 고치고, 학습 돌리고, 결과 확인하고, 유지할지 버릴지 판단하고. 하루에 할 수 있는 실험 횟수에는 한계가 있고, 대부분은 GPU 앞에서 기다리는 시간입니다.
AI 도구가 연구 과정에 들어오면서 이 풍경이 바뀌기 시작했습니다. 2025년 Nature Human Behaviour에 발표된 연구에 따르면, 컴퓨터 과학 논문의 약 5분의 1이 이미 LLM이 개입된 콘텐츠를 포함하고 있습니다. Science에 발표된 별도의 분석에서는, AI 도구를 사용하는 연구자들의 논문 생산량이 분야에 따라 30~50% 증가했다는 결과도 나왔습니다. 하지만 이건 아직 "사람이 AI를 보조 도구로 쓰는" 수준입니다.
최근에는 한 발 더 나아가서, 연구의 핵심 루프 자체를 AI 에이전트에게 통째로 넘기는 프로젝트들이 등장했습니다.
Andrej Karpathy의 autoresearch는 공개 직후 GitHub 스타 6만 이상을 찍으며 커뮤니티를 뒤흔들었고, Sakana AI의 AI Scientist는 AI가 쓴 논문이 학회 피어리뷰를 통과한 뒤 2026년 3월 Nature에 게재되었습니다. autoresearch는 실험 루프 하나를 깊게 파고, AI Scientist는 아이디어부터 논문까지 전 과정을 커버합니다.
접근은 다르지만, 둘 다 "AI가 연구의 핵심 루프를 직접 돌린다"는 점에서는 같은 방향을 가리키고 있습니다. 각각이 어디까지 도달했고, 어디서 막혀 있는지를 정리해봤습니다. 이 글을 읽고 나면, 두 프로젝트의 작동 원리와 한계를 파악하고 자기 업무에 어떻게 가져갈 수 있을지 판단하는 데 도움이 될 겁니다. autoresearch와 AI Scientist 각각의 구조부터 시작해서, 둘의 비교, 한계, 그리고 실무 시사점 순서로 풀어보겠습니다.
autoresearch는 어떻게 작동하는가?
한 줄로 요약하면, 밤새 쉬지 않고 실험을 돌리는 AI 인턴 연구원입니다.
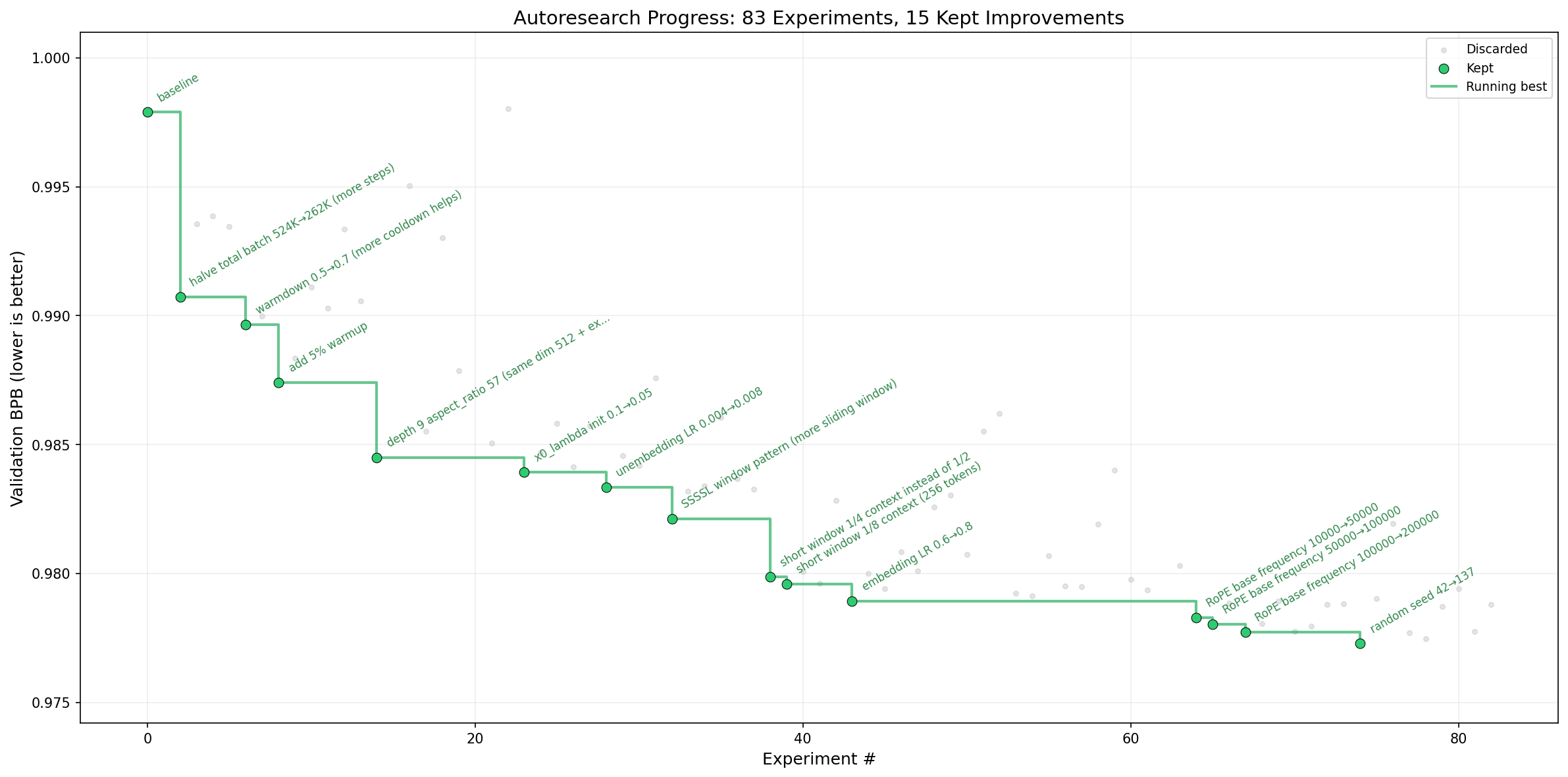
사람이 할 일은 딱 하나. 마크다운 파일(program.md)에 연구 방향을 자연어로 적는 것. 나머지는 에이전트가 알아서 합니다.
- 코드를 수정하고 (train.py)
- 5분간 학습을 돌리고
- 성능(val_bpb, validation bits per byte라는 언어모델 품질 지표)이 오르면 keep, 아니면 discard
- 모든 실험은 git commit으로 기록
이걸 사람이 자는 동안 수백 번 반복합니다. 아침에 일어나서 git history만 확인하면 됩니다.
여기서 git을 실험 기록에 쓰는 설계가 꽤 영리합니다. 단순 로깅이 아니라, 에이전트에게 context window 밖의 장기 기억을 제공하는 구조이기 때문입니다. LLM 에이전트의 고질적 한계가 컨텍스트 길이인데, git history가 "지금까지 뭘 시도했고, 뭐가 먹혔는지"를 외부에 저장하는 메모리 역할을 합니다. 에이전트가 과거 실험을 참조해서 다음 방향을 결정할 수 있는 거죠.
https://github.com/karpathy/autoresearch
autoresearch의 실제 결과는?
Karpathy는 이미 충분히 다듬어둔 nanochat 학습 코드에 이 시스템을 적용했습니다.
- ~700회 자율 실험 수행, 약 20개 개선 발견
- GPT-2 품질 도달 시간 2.02h → 1.80h (11% 속도 향상)
- 본인이 몇 달간 놓친 코드 버그(QK-Norm의 scalar multiplier 누락)를 에이전트가 발견
커뮤니티 반응도 빨랐습니다. Shopify CEO Tobi Lutke는 공개 당일 밤 자사 모델에 적용해 37회 실험으로 19% 개선을 달성했고, 이후 템플릿 엔진 Liquid에 적용해 렌더링 속도를 53% 끌어올렸습니다. Apple Silicon, Windows, AMD GPU 포트도 커뮤니티에서 자생적으로 등장했고, awesome-autoresearch에 정리된 것처럼 코드 최적화, 보안 등 다양한 도메인으로 패턴이 퍼지고 있습니다.
다음 단계: AgentHub와 에이전트 연구 커뮤니티
Karpathy는 autoresearch의 다음 방향도 밝혔습니다. 현재 autoresearch는 단일 에이전트가 하나의 연구 경로를 순차적으로 파는 구조입니다. 하지만 Karpathy가 구상하는 건 훨씬 큽니다.
"목표는 단일 PhD 학생을 모방하는 게 아니라, PhD 학생들의 연구 커뮤니티를 모방하는 것이다."
SETI@home처럼 여러 에이전트가 서로 다른 연구 방향을 비동기적으로 탐색하고, 결과를 공유하면서 협업하는 구조입니다. 이를 위해 Karpathy는 AgentHub라는 에이전트 전용 협업 플랫폼을 프로토타이핑하고 있습니다. GitHub의 브랜치/PR/머지 구조가 인간 협업에 맞춰져 있다면, AgentHub는 에이전트 스웜에 맞춰 DAG 형태의 커밋 구조 + 메시지 보드로 설계되어 있습니다.
아직 초기 스케치 단계이긴 합니다. 하지만 "단일 에이전트의 반복 실험"에서 "에이전트 커뮤니티의 분산 연구"로 넘어가려는 방향성은 분명합니다.
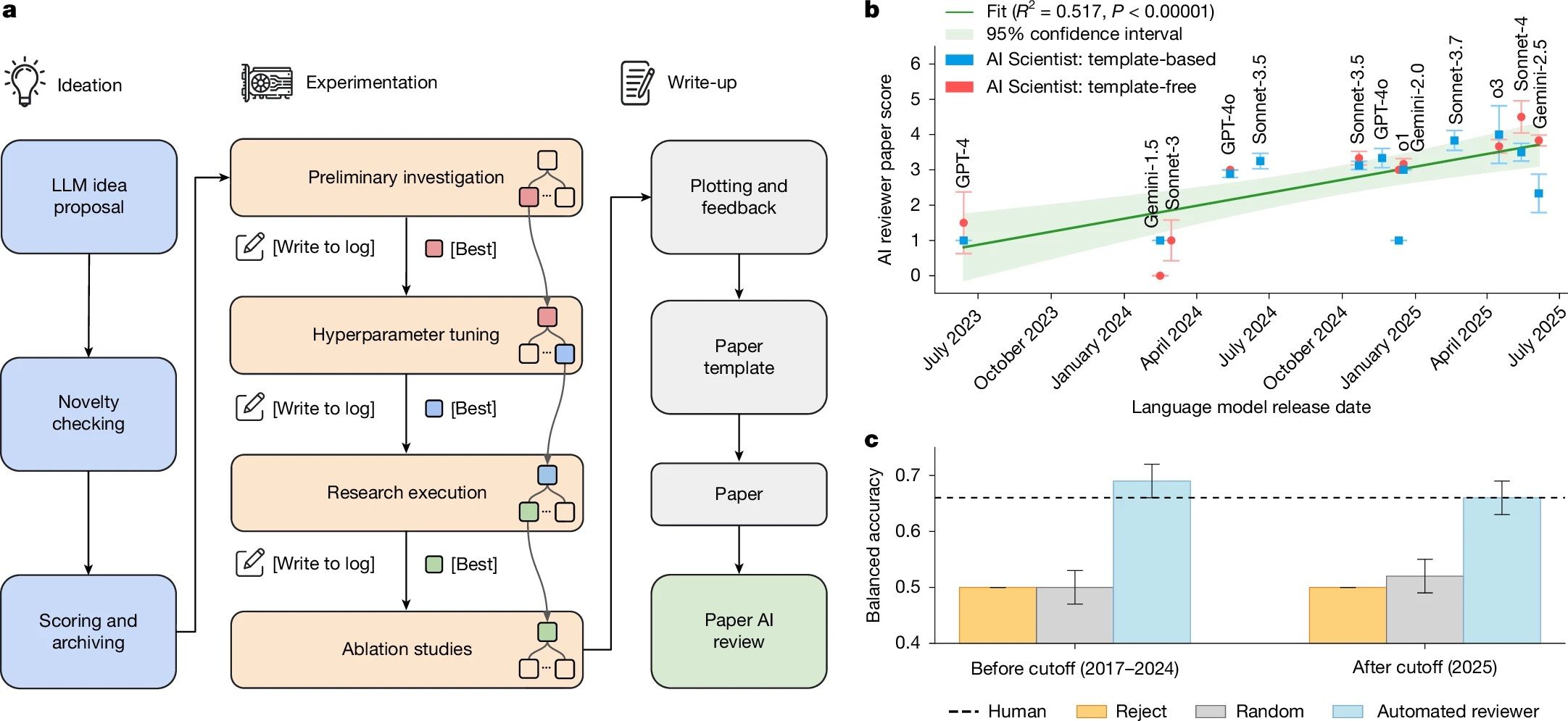
AI Scientist는 어떤 과정을 자동화하는가?
autoresearch가 실험 루프 하나를 깊게 파는 시스템이라면, AI Scientist는 다른 병목을 겨냥합니다. ML 연구에서 실험만 시간이 드는 건 아닙니다. 문헌 조사, 아이디어 구체화, 논문 작성, 리뷰 대응까지. 연구 논문 한 편이 나오기까지의 전체 파이프라인을 AI Scientist는 자동화합니다. 논문 1편 생성 비용은 약 $15.
파이프라인은 네 단계입니다.
- 아이디어 생성: LLM이 연구 아이디어를 여러 개 만들고, Semantic Scholar API로 기존 논문과 중복을 자동 검사합니다. 너무 비슷한 건 이 단계에서 걸러냅니다.
- 실험 실행: 살아남은 아이디어로 LLM이 코드를 처음부터 직접 작성하고 실험합니다. 여러 경로를 트리 형태로 동시에 탐색하는 agentic tree search 구조를 사용하는데, 실험 방향이 막다른 길인지 미리 여러 갈래를 동시에 시도해보는 방식이라고 이해하면 됩니다.
- 논문 작성: 실험 노트와 결과 플롯을 바탕으로 학술 논문 형식의 원고를 자동 생성합니다. 관련 연구 인용까지 자동입니다.
- 자동 리뷰: Automated Reviewer가 논문 품질을 학회 리뷰 기준으로 평가합니다. 이 리뷰어의 판정 정확도는 실제 인간 리뷰어와 동등한 수준으로 검증되었습니다.
Paper: Lu, C. et al. "Towards end-to-end automation of AI research." Nature 651, 914 (2026)
AI가 쓴 논문이 학회 피어리뷰를 통과했다?
AI Scientist가 주목받은 결정적 이유입니다.
연구팀은 ICLR 2025 운영진의 동의와 IRB 승인을 받고, AI 생성 논문 3편을 ICBINB 워크샵에 제출했습니다. 리뷰어들에게는 일부 제출물이 AI 생성이라는 사실만 알렸고, 어떤 논문인지는 블라인드 처리했습니다.
결과: 3편 중 1편이 인간 평균 acceptance 점수를 넘었습니다. 이 결과를 포함한 논문이 2026년 3월 Nature에 오픈 액세스로 게재되었고, 학계가 이 방향을 공식적으로 인정한 시그널로 받아들여지고 있습니다.
그리고 이 시스템에서 재미있는 지점이 하나 더 나왔습니다. base LLM 성능이 올라갈수록 AI Scientist가 생성하는 논문 품질도 비례해서 올라갑니다 (P < 0.00001). 이게 중요한 이유는, 시스템 자체를 따로 개선하지 않아도 foundation model이 발전하는 것만으로 출력 품질이 좋아진다는 뜻이기 때문입니다. 다시 말해, AI Scientist는 base model 발전에 "무임승차"할 수 있는 구조입니다. 이 시스템의 수명과 확장성을 낙관적으로 볼 수 있는 근거이기도 합니다.
두 프로젝트가 공통으로 보여주는 것
autoresearch는 실험 루프를 깊게 700번 반복하고, AI Scientist는 아이디어부터 논문까지 한 번에 관통합니다. 커버하는 범위도 다르고 출력물도 다르지만, 밑바닥의 구조는 같습니다. LLM이 코드를 쓰고, 실행해서 숫자를 얻고, 그 피드백으로 다음 행동을 결정하는 루프. 둘 다 이 루프 위에서 돌아갑니다.
둘 다 ML 실험에서 출발한 것도 우연이 아닙니다. ML 실험은 평가 지표가 명확하고, 코드 수정만으로 실험이 완결되며, 물리적 장비 없이 컴퓨터 안에서 전체 사이클이 돌아갑니다. 에이전트가 자율적으로 루프를 돌리기에 이상적인 조건이죠. 반대로, 웻랩이 필요한 생물학이나 현장 데이터 수집이 필요한 사회과학 같은 분야로의 확장은 아직 먼 이야기입니다.
AI 연구 자동화, 아직 풀리지 않은 문제들
메트릭 최적화가 곧 좋은 연구인가?
autoresearch는 학습 손실(val_bpb)을, AI Scientist는 자동 리뷰 점수를 최적화합니다. 에이전트 입장에서는 이 숫자를 낮추는 게 유일한 목표입니다. 문제는, 숫자가 낮아졌다고 해서 그게 의미 있는 발견인지는 별개라는 점입니다. 예를 들어, autoresearch가 이미 알려진 트릭(learning rate scheduling 조정 등)을 재발견해서 loss를 줄이는 건 "새로운 발견"이 아니라 "기존 지식의 재탐색"에 가깝습니다. AI Scientist도 마찬가지로, 리뷰 점수를 높이기 위해 안전하고 피상적인 아이디어만 양산할 수 있습니다.
Goodhart's Law가 여기에 정확히 적용됩니다.
"측정 지표가 목표가 되는 순간, 좋은 측정 지표이기를 멈춘다."
현재 시스템들은 "좋은 연구란 무엇인가"를 판단하지 못하고, 대신 숫자 하나를 줄이는 데 최적화되어 있습니다. 이건 구조적 한계입니다.
AI 생성 논문의 저자는 누구인가?
AI Scientist의 Nature 게재는 연구 윤리 질문도 열었습니다. AI 생성 논문의 저자권, 대량 제출 시 리뷰 시스템 과부하, disclosure 정책. 학회 수준의 합의는 아직 없는 상황입니다. AI Scientist 연구팀은 이 문제를 의식해서, ICLR에 제출한 AI 생성 논문 3편 모두 결과와 무관하게 피어리뷰 후 철회하기로 사전에 결정했고, IRB 승인도 받았습니다. 하지만 이건 개별 연구팀의 자율 조치일 뿐, 학회 차원의 정책은 여전히 정비 중입니다.
아직은 컴퓨터 안에서 완결되는 실험에 한정된다
두 시스템 모두 코드를 고치고 GPU에서 돌리면 끝나는 ML 실험에 맞춰져 있습니다. 앞서 비교 섹션에서 짚었듯이, ML 실험은 평가 지표가 명확하고, 코드 수정만으로 실험이 완결되며, 물리적 장비 없이 전체 사이클이 컴퓨터 안에서 돌아갑니다. 이 조건이 갖춰지지 않는 분야, 예를 들어 웻랩에서 시약을 다뤄야 하는 생물학이나, 현장 데이터 수집이 필요한 사회과학 같은 분야에는 바로 적용하기 어렵습니다. 연구 자동화가 ML을 넘어 확장되려면, 물리적 실험을 로봇이 수행하거나 시뮬레이션으로 대체하는 별도의 인프라가 필요합니다.
그래서 AI가 연구를 수행하는 시대에서, 사람의 역할은 무엇인가?
한계는 분명합니다. 그러나 autoresearch가 GitHub 스타 6만을 넘기고, AI Scientist가 Nature에 실리는 건, 이 방향 자체가 이미 트렌드로 자리잡고 있다는 뜻입니다. 이러한 상황에서 두 프로젝트가 던지는 질문은: 이 흐름 속에서 사람이 어떤 역할을 맡게 될 것인가? 입니다. 무엇을 연구할지, 어떤 지표가 의미 있는지, 결과를 어떻게 해석할지. 이건 여전히 사람의 몫입니다.
Karpathy의 표현을 빌리면, 연구자의 역할은 코드를 직접 쓰는 writer에서, 에이전트를 지휘하는 director로, 그리고 연구 방향을 설계하는 research advisor로 이동하고 있습니다. 사람의 역할이 사라지는 게 아니라, 실행에서 설계로 이동하는 겁니다.
한계는 분명하지만, 그래도 실무에 가져갈 수 있는 부분이 있습니다.
AI 연구 자동화를 실무에 어떻게 적용할 수 있을까?
연구 조직: 반복 실험은 에이전트에게, 방향 설계는 사람에게
autoresearch가 보여준 핵심은, 연구자의 가치가 "실험을 돌리는 것"이 아니라 **"좋은 program.md를 쓰는 것"**에 있다는 점입니다. 구체적으로 program.md를 쓴다는 건 이런 걸 의미합니다.
- 탐색 범위 정의: "attention mechanism을 최적화하라" vs "모델 전체를 자유롭게 바꿔라"
- 금지 조건 설정: "tokenizer는 건드리지 마라", "파라미터 수를 2배 이상 늘리지 마라"
- 평가 메트릭 선택: 어떤 숫자가 "더 나아졌다"를 의미하는지 결정
메트릭이 명확한 반복 실험(하이퍼파라미터 탐색, 아키텍처 변형 테스트 등)은 에이전트에게 맡기고, 연구자는 이 방향 설계에 집중하는 구조를 시도해볼 수 있습니다. 특히 이미 잘 정리된 코드베이스가 있고, 개선 방향만 정의하면 되는 상황이라면 autoresearch 패턴이 바로 적용 가능합니다.
엔지니어: ML 실험을 넘어선 패턴의 확장
autoresearch 패턴은 ML에 한정되지 않습니다. "수치로 판단 가능한 최적화 목표"가 있는 코드라면 어디든 적용 가능합니다. Shopify가 Liquid 템플릿 엔진에 적용해 렌더링 속도 53%를 끌어올린 게 대표적입니다. 렌더링 속도처럼 수치로 판단 가능한 목표가 있다면, ML이 아닌 코드베이스에도 같은 패턴을 적용할 수 있습니다. API 응답 시간, 빌드 속도, 메모리 사용량 같은 지표가 명확한 영역이라면 시도해볼 만합니다.
PM/기획자: R&D 초기 스크리닝에 AI Scientist 패턴 접목하기
AI Scientist 방식의 아이디어 탐색을 사내 R&D에 접목할 수도 있습니다. 예를 들어, 신규 모델 아이디어를 LLM이 다수 생성하고 기존 문헌과 자동 비교한 뒤 유망한 후보만 걸러내는 초기 스크리닝 단계를 도입하면, 연구자가 문헌 조사에 쓰는 시간을 줄일 수 있습니다. AI Scientist의 Semantic Scholar API 활용 방식처럼, 기존 논문과의 중복/유사도를 자동으로 체크하는 것만으로도 초기 아이디어 필터링 비용이 크게 줄어듭니다.
마무리
두 프로젝트를 보면서 느낀 건, AI 연구 자동화가 발전할수록, 사람이 문제를 정의하고 의미를 판단하는 역할이 오히려 더 중요해집니다. 그리고 Karpathy가 AgentHub를 통해 구상하는 것처럼, 에이전트들이 서로 실험 결과를 공유하고 연구 방향을 협의하는 "PhD 학생들의 연구 커뮤니티를 에뮬레이트"하는 단계가 온다면, 인간 연구자의 역할은 또 한 번 재정의될 겁니다.
참고문헌
- Karpathy, A. (2026). autoresearch. GitHub. https://github.com/karpathy/autoresearch
- Karpathy, A. (2026). AgentHub. GitHub. x.com/karpathy/status/2030705271627284816
- Karpathy, A. (2026). "The goal is not to emulate a single PhD student..." X. https://x.com/karpathy/status/2030705271627284816
- Lutke, T. (2026). autoresearch 적용 결과. X. https://x.com/tobi/status/2030771823151853938
- Lu, C. et al. (2026). "Towards end-to-end automation of AI research." Nature, 651, 914. https://doi.org/10.1038/s41586-026-10265-5
- SakanaAI. AI-Scientist-v2. GitHub. https://github.com/SakanaAI/AI-Scientist-v2
- Semantic Scholar. https://www.semanticscholar.org/
- Liang, W. et al. (2025). "Monitoring AI-modified content in academic publishing." Nature Human Behaviour. https://www.science.org/content/article/one-fifth-computer-science-papers-may-include-ai-content
- Yin, Y. et al. (2025). AI-assisted research productivity study. Science. https://www.euronews.com/next/2025/12/31/scientists-are-publishing-more-than-ever-with-ai-but-not-all-papers-measure-up-study-finds
- Fortune. (2026). "Why everyone is talking about Andrej Karpathy's autonomous AI research agent." https://fortune.com/2026/03/17/andrej-karpathy-loop-autonomous-ai-agents-future/
- awesome-autoresearch. GitHub. https://github.com/alvinreal/awesome-autoresearch