AI Insight
웹에서 행동하는 Agentic AI의 시대

AI가 브라우저를 직접 조작하는 시대
AI에게 "이걸 설명해줘"가 아니라 "이 일을 해줘"라고 말하기 시작한 적이 있으신가요?
그동안 AI의 발전은 더 많은 지식, 더 긴 문맥, 더 정확한 답변으로 측정되어 왔습니다. 하지만 지금 웹에서 일어나는 변화는 다릅니다.
모델이 얼마나 똑똑한가를 넘어, 그 지능이 실제 작업을 수행할 수 있는가가 핵심 질문이 되고 있습니다.
채팅창 안에서 답변을 생성하던 AI는 이제 브라우저를 열고 여러 단계의 웹 작업을 직접 수행하기 시작했습니다.
- 실제로 2025년, 웹과 상호작용하는 AI agent 트래픽은 전년 대비 7,851% 증가했습니다.
- 이 중 77%는 상품·검색 페이지에서, 8.8%는 계정 페이지, 2.3%는 체크아웃 페이지에서 발생했습니다.
이는 에이전트의 활동이 정보 수집을 넘어 실제 거래 흐름에 진입하며 웹 위에서 행동하는 실행 주체가 되고 있다는 뜻입니다. 이런 흐름은 이미 여러 제품에서 구체화되고 있습니다. Anthropic의 Claude for Chrome, Google의 Project Mariner, 그리고 최근 공개된 OpenClaw까지, AI가 브라우저 위에서 직접 작업을 수행하는 시대가 본격적으로 열리고 있습니다.
OpenClaw는 왜 60일 만에 GitHub 스타 25만을 찍었을까?

이 중 OpenClaw가 특히 주목받는 이유도 분명합니다.
WhatsApp이나 Telegram 같은 메신저에서 "다음 주 도쿄행 최저가를 찾아줘" 라고 말하면, OpenClaw는 실제로 브라우저를 열고, 출발지와 목적지를 입력하고, 캘린더에서 날짜를 선택하고, 검색 결과를 필터링한 뒤 결과를 메신저로 돌려줍니다.
이것이 가능한 이유는 OpenClaw가 Chrome DevTools Protocol(CDP)과 Playwright를 기반으로 실제 브라우저를 직접 제어하기 때문입니다. 한 마디로, AI가 사람처럼 브라우저를 열고 마우스와 키보드로 웹을 조작하는 것입니다. 폼 입력, 버튼 클릭, 페이지 탐색까지, 사람이 하던 웹 작업을 그대로 자동화할 수 있습니다.
OpenClaw는 AI가 지식 인터페이스에서 실행 인터페이스로 이동하고 있다는 사실을, 대중이 직접 체감할 수 있는 형태로 보여준 사례입니다.
그러나 OpenClaw 같은 프레임워크는 LLM에게 브라우저를 조작할 수 있는 통로를 열어줄 뿐, LLM 자체의 웹 행동 능력을 높여주지는 않습니다. 결국 에이전트가 복잡한 웹 환경에서 안정적으로 작동하려면, LLM이 웹 위에서 행동하는 법을 직접 학습해야 합니다.
모델에게 부족한 건 지식이 아니라 행동
그렇다면 웹에서 행동하는 능력은 어떻게 학습시킬 수 있을까요?
LLM은 이미 인터넷 전체에서 압축한 방대한 지식을 보유하고 있습니다. 하지만 그 지식을 실제 웹 환경에서 구체적인 행동으로 수행하는 것은 전혀 다른 차원의 문제입니다.
그리고 최근에 이러한 문제 의식을 다룬 논문이 있습니다.
WebFactory에서는 이 문제를 semantic-to-action gap이라 부릅니다. LLM은 GUI 인터랙션에 대해 알고 있지만, 복잡하고 동적인 GUI 환경에서 이를 수행하는 능력, 즉 grounding이 빠져 있다는 것입니다.
예를 들어, 모델은 "항공편을 검색하려면 출발지와 목적지를 입력하고 날짜를 선택한 뒤 검색 버튼을 클릭한다"고 설명할 수 있지만, 실제 항공권 사이트 앞에서 날짜 선택 캘린더를 열고, 정확한 좌표를 클릭하고, 필터를 적용하는 일련의 행동을 안정적으로 실행하는 것은 별개의 역량입니다.
WebFactory는 이미 보유한 지식을 실제 환경에서 행동하는 능력으로 압축하는 intelligence compression이라는 개념을 제안합니다. 이 관점에서, 에이전트 학습의 핵심 축을 모델의 크기나 지능 자체가 아니라, 그 지식이 실제 행동으로 전환되는 효율로 설명합니다.
지식 → 행동 전환을 위해서는 어떤 것이 필요할까?
우선 에이전트가 웹 위에서 반복적으로 행동을 시도하고 피드백을 받을 수 있는 훈련 환경이 필요합니다. 그런데 현재의 두 경로 모두 한계가 있습니다. 사람이 직접 만들면 정밀하지만 확장이 어렵고, 실제 웹을 그대로 쓰면 같은 페이지도 시점에 따라 달라지기 때문에 체계적인 훈련과 평가가 어렵습니다.
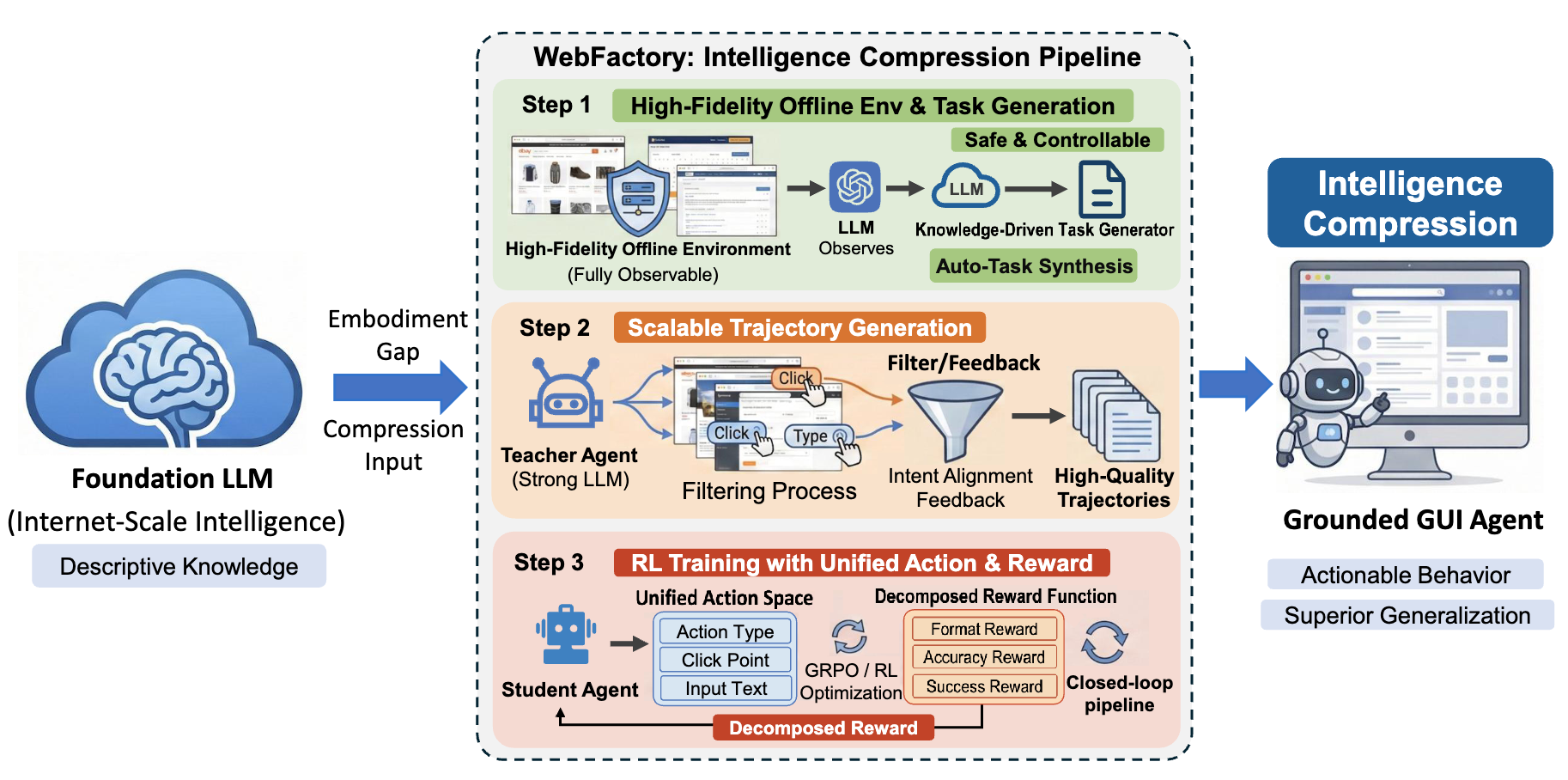
WebFactory의 파이프라인은 다음과 같은 단계로 구성됩니다:
- 환경 구축 - 실제 웹과 닮았지만 실험 가능한 offline 환경을 만듭니다.
- 태스크 생성 - 사이트의 구조 정보(knowledge)와 콘텐츠 정보(data)를 함께 사용해 수행·검증 가능한 태스크를 만듭니다.
- 행동 궤적 생성 - Teacher agent가 환경에서 행동 궤적 데이터를 생성합니다.
- 에이전트 학습 - 그 데이터를 바탕으로 세분화된 reward를 사용하는 Reinforcement Learning으로 student agent(LLM)을 학습합니다.
1. 좋은 데이터는 어떤 차이를 만들까?
WebFactory는 구조 정보와 콘텐츠 정보를 함께 활용하게 되면서 태스크의 실행 가능성과 검증 가능성이 크게 높아졌다고 보고합니다. 이는 웹 에이전트에서 중요한 것이 단순한 데이터 양이 아니라, 실제로 수행 가능하고 신뢰할 수 있는 task를 얼마나 잘 구성하느냐에 있음을 보여줍니다.
행동 궤적의 품질에서도 같은 패턴이 나타납니다. 더 잘 설계된 생성 과정은 성공률을 높이고 불필요한 행동을 줄이며, 학습에 쓸 수 있는 유효 데이터를 늘립니다.
이러한 데이터를 기반으로 학습된 WebFactory-3B는:
- 사람이 직접 라벨링한 데이터 기반으로 학습된 모델과 비슷하거나 더 나은 수준의 성능을 보였고
- 실제 온라인 플랫폼으로 옮겼을 때도 강한 전이 성능을 보였습니다.
2. Embodiment potential: 모델마다 다른 전환력
흥미로운 점은, 동일한 student agent(Qwen2.5-VL-3B)를 두고도 어떤 foundation model이 데이터 생성 파이프라인을 이끌었는지에 따라 최종 성능이 달라질 수 있는지를 실험했다는 점입니다. GPT-5, Claude Opus 4.1, Claude Sonnet 4를 각각 WebFactory 파이프라인 전반에 적용한 결과, 이후 학습된 agent의 성능은 벤치마크 전반에서 차이를 보였습니다.
- GPT-5가 type accuracy, step completion, grounding accuracy의 대부분 지표에서 가장 강한 성능을,
- Claude Opus 4.1은 그보다 다소 낮지만 비교적 안정적인 결과를,
- Claude Sonnet 4는 더 큰 변동성을 보였습니다.
논문은 이 성능 차이를 foundation model 고유의 속성으로 보고, 각 모델이 자신의 지식을 행동 가능한 에이전트로 전환하는 잠재력을 embodiment potential이라 부릅니다. 모델마다 환경, task, trajectory를 생성하는 품질이 다르고, 그 차이가 최종 agent 성능으로 이어진다는 해석입니다.
AI Agent의 경쟁력은 어디서 오는가?
이 결과는 한동안 LLM 발전을 이끌어온 scaling law의 관점만으로는 웹 에이전트 학습을 충분히 설명하기 어렵다는 점을 시사합니다. 이제 LLM 자체는 점차 commodity가 되고 있습니다. 같은 모델을 누구나 API로 호출할 수 있는 시대에, 웹 에이전트의 경쟁력은 모델 자체보다 그 지식을 실제 행동으로 연결하는 파이프라인의 정교함에 달려 있습니다.
그리고 이 경쟁은 이제 막 시작되었습니다. OpenClaw가 보여준 것처럼 사용자는 이미 AI에게 행동을 기대하고 있고, WebFactory가 보여준 것처럼 그 행동을 학습시키는 방법론도 구체화되고 있습니다.
앞으로의 질문은 "어떤 모델이 더 똑똑한가"가 아니라, "어떤 시스템이 지식을 행동으로 더 잘 바꾸는가"가 될 것입니다.